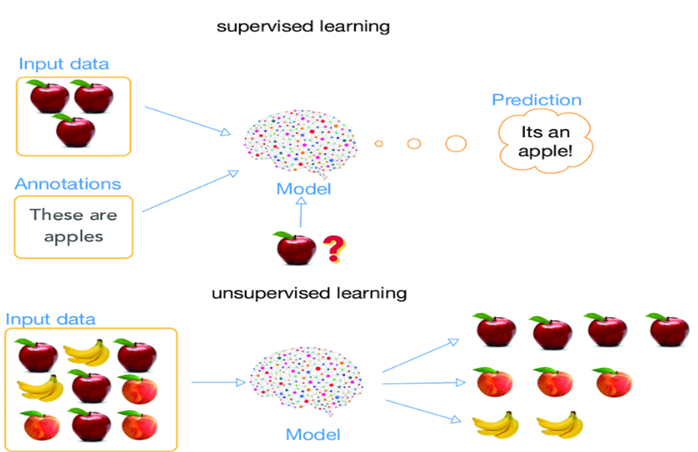
Makine öğrenimi, veriye dayalı sistemlerin güçlü bir temelini oluştururken, etiketlenmiş veri elde etmek genellikle zaman alıcı ve maliyetlidir. Bu sınırlama, yarı denetimli öğrenme gibi tekniklerin ortaya çıkmasına neden olmuştur. Bu teknikler, kısıtlı miktardaki etiketlenmiş verinin yanı sıra bol miktarda etiketlenmemiş veriden faydalanarak model performansını geliştirmeyi amaçlar. Bu yazıda, yarı denetimli öğrenmenin ne olduğunu, nasıl çalıştığını ve gerçek dünya uygulamalarında nasıl kullanılabileceğini inceleyeceğiz.
Yarı Denetimli Öğrenme Nedir?
Yarı denetimli öğrenme, denetimsiz öğrenme ve denetimli öğrenme arasında bir köprü kuran ve hem etiketlenmiş hem de etiketlenmemiş verilerden yararlanarak modellerin eğitildiği bir makine öğrenimi yaklaşımıdır. Bu yöntem, etiketli verilerin sınırlı olduğu durumlarda, büyük miktarda etiketsiz veriden de faydalanarak modellerin performansını önemli ölçüde arttırır.
Avantajları Nelerdir?
- Etiketleme maliyetini düşürür: Büyük veri kümelerini etiketlemek yerine, sadece küçük bir kısmını etiketlemek yeterlidir. Bu sayede zaman ve iş gücü maliyetlerinde önemli bir tasarruf sağlanır.
- Daha fazla veriyi kullanır: Etiketlenmemiş verileri de kullanarak, modelin daha geniş bir bilgi yelpazesiyle eğitilmesini sağlar.
- Daha karmaşık problemleri çözebilir: Etiketlenmemiş verilerdeki örüntüleri çözerek, modelin daha önce fark edilmemiş örüntüleri keşfetmesine yardımcı olur.
- Genelleme Yeteneği: Yarı denetimli öğrenme, modelin daha genel ve çeşitli veri dağılımlarından öğrenmesini sağlar. Bu da modelin daha iyi genelleme yapmasını ve gerçek dünya verilerinde daha iyi performans göstermesini sağlar.
Nasıl Çalışır?
Yarı denetimli öğrenme, genellikle iki adımda gerçekleşir: Öncelikle, bir miktar etiketlenmiş veriyle bir başlangıç model eğitilir ve ardından bu model, etiketlenmemiş veriyi kullanarak kendisini geliştirir. Bu süreçte, sözde etiketleme, kendi kendini eğitme ve graf tabanlı yöntemler gibi çeşitli teknikler kullanılabilir.
- Sözde Etiketleme: Etiketlenmemiş verileri manuel olarak etiketlemek yerine, modele etiketli verilerden yola çıkarak yaklaşık etiketler verilen bir tekniktir. İşlem adımları şu şekildedir:
İlk adımda, model etiketli verilerle eğitilir.
Ardından, eğitilmiş modeli kullanarak etiketlenmemiş verilere sözde etiketler verilir. Bu aşamada, elde edilen tahminlere "sözde etiketler" denir, çünkü bunlar orijinal etiketli verilerden türetilmiştir.
Son olarak, model bu sözde etiketlerle birlikte tekrar eğitilir.
Bu süreç, modelin performansının artması ve daha yüksek doğruluk seviyelerine ulaşıncaya kadar tekrarlanır.
- Kendi Kendini Eğitme: Sözde etiketlemeye benzer ancak bir farkla: Kendi kendine eğitimde, modelin yalnızca yüksek güven düzeyine (Örneğin, bir model bir kuş görüntüsünü %60 olasılıkla tahmin ettiğinde, bu tahminin güven düzeyi %60 olarak ifade edilir, yani modelin bu tahmini %60 olasılıkla doğru olduğunu düşündüğünü gösterir.) sahip tahminleri kabul edilir. Ayrıca bu işlem birkaç kez tekrarlanarak modelin performansı daha da iyileştirilir. Peki nasıl çalışır?
İlk olarak, sınırlı sayıda etiketli veri örneği seçilir. Bu küçük veri seti, başlangıç bir model oluşturmak için geleneksel denetimli öğrenme yöntemleriyle eğitilir.
Sonrasında, kısmen eğitilmiş model kullanılarak, henüz etiketlenmemiş veri setinin geri kalanı için tahminler üretilir. Yine burada da elde edilen tahminlere "sözde etiketler" denir.
Daha sonra modelin en güvenilir tahminleri seçilir. Herhangi bir sözde etiket bu güven eşiğini aşıyorsa, bu etiketler etiketli veri setine eklenir ve birleştirilmiş bir veri kümesiyle geliştirilmiş bir model eğitmek için kullanılır.
Bu süreç, birkaç tekrarla giderek artan miktarda sözde etiketin eklenmesiyle gerçekleşir. Veriler uygun olduğunda, modelin performansı her tekrarda artmaya devam edecektir.
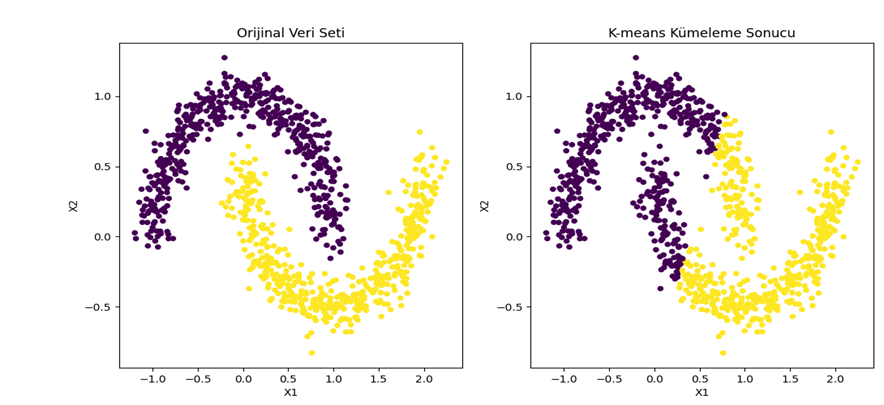
- Graf Tabanlı Yöntemler: Bu yöntemlerde, veriler graf yapısında temsil edilir ve benzer özelliklere sahip noktalar birbirine bağlanır. Etiketlenmiş örneklerden başlayarak, graf yapısı kullanılarak etiketlenmemiş verilere etiketler atanır. Model yeni etiketlenen verileri kullanarak tekrardan eğitilir. Bu süreç modelin performansı gelişene kadar tekrarlanır.
Gerçek Dünya Uygulamaları
Yarı denetimli öğrenme, etiketlenmemiş verilerin bolluğu ve erişiminin kolaylığı sayesinde, birçok gerçek dünya uygulama alanında yaygın olarak kullanılabilir. Örneğin, elimizde çok miktarda etiketlenmemiş veri ve sınırlı sayıda etiketlenmiş veri varsa, bu durum da problemin çözümü için çeşitli yarı denetimli algoritmaları kullanmak mantıklı olabilir. Örnek olarak tıp (hastalık tespiti), görüntü işleme (nesne tanıma, yüz tanıma), doğal dil işleme (dil çevirisi, metin sınıflandırma) gibi çeşitli uygulama alanlarında kullanılabilir.
İş Senaryolarında Potansiyel Uygulamalar
- E-ticarette müşteri duygularının analizi
Diyelim ki bir e-ticaret şirketi, müşterilerin ürünler hakkındaki duygu ve tercihlerini anlamak için yorumları analiz etmek istiyor. Mevcut yorumların çoğu etiketlenmemiş. Etiketlenmiş olanlar ise sadece küçük bir kısmı oluşturuyor. Bu durumda yarı denetimli öğrenme kullanılabilir. Öncelikle, küçük bir etiketlenmiş veri setiyle bir duygu analizi modeli eğitilir. Ardından, bu model, etiketlenmemiş yorumlar üzerinde tahminler yapmak için kullanılır. Tahminler daha sonra elle doğrulanır ve doğrulanmış olanlar etiketlenmiş veri setine eklenir. Bu doğrulanmış verilerle model yeniden eğitilir ve performansı artırılır. Bu süreç, modelin daha fazla etiketlenmiş veriyle geliştirilmesi ve daha geniş bir yelpazede yorumları analiz etmesi için tekrarlanır. Sonuç olarak, şirket müşteri geri bildirimlerini daha etkili bir şekilde değerlendirebilir ve ürünlerini geliştirmek için daha iyi kararlar alabilir.
- Sürücüsüz araç geliştirme
Sürücüsüz araçlar, çeşitli sensörler aracılığıyla çevrelerini algılar ve bu verileri işleyerek güvenli bir şekilde sürüş yaparlar. Ancak, sürücüsüz araçların karşılaşabileceği durumların her birini etiketlemek ve modeli eğitmek oldukça maliyetlidir. Yarı denetimli öğrenme, bu durumda devreye girer. Şirket, sınırlı sayıda etiketlenmiş veriyle başlayarak bir sürücüsüz araç modeli oluşturur. Bu model, gerçek dünya verilerinden elde edilen etiketlenmemiş verileri kullanarak sürüş senaryolarını tahmin etmek için kullanılır. Uzmanlar, modelin yanlış tahminlerini düzeltir ve doğrulanmış senaryoları etiketlenmiş veri setine ekler. Bu doğrulanmış verilerle model yeniden eğitilir ve performansı artırılır. Bu süreç, modelin daha fazla etiketlenmiş veri ile geliştirilmesini sağlar. Bu senaryoda, yarı denetimli öğrenme sürücüsüz araçların daha güvenli bir şekilde sürüş yapmasına yardımcı olurken, aynı zamanda eğitim maliyetlerini de azaltır.
Sonuç
Yarı denetimli öğrenme, yapay zekanın sınırlarını genişletmek için büyük bir potansiyele sahiptir. Bu yöntem etiketlenmiş verinin sınırlı olduğu durumlarda makine öğrenimi modellerinin performansını artırmak için güçlü bir araç olarak kullanılmaktadır. Ancak, yarı denetimli öğrenme de diğer algoritmalar gibi mükemmel değildir. Algoritmanın sağladığı sonuçlar, %100 doğru etiketler üretip üretmediğini doğrulamak için bir yöntem olmaması sebebiyle, daha az güvenilirdir ve %100 güvenilir değildir. Sonuç olarak her algoritmanın kendi avantajları ve dezavantajları vardır ve probleme uygun algoritmanın seçilmesi önemlidir.


.png)






.png)
.png)


 Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)


 SMEMA Nedir?
SMEMA Nedir?.png)
.png)