Bu blog yazımızda, ilkokul çağındaki çocuklardan teknik konularda çalışan birçok profesyonele kadar geniş bir yelpazede etkisini hissettiren büyük dil modellerinden bir nebze bahsedeceğiz. Gerçi büyük bir derya deniz olan bu konu ne kadar özetlenebilir sorusu hepimizin aklına gelebilir. Burada amacımız deniz kenarında gezintiye çıkmış birine bir nebze martıların seslerini dinleterek bir bakış açısı vermektir. Ayrıca kısaca tarihi serencamından da bahsederek kullanım alanları, çalışma mekanizması, teknik bazı terimleri ve örnek bir kod vererek çalışmasından bahsedilecektir.
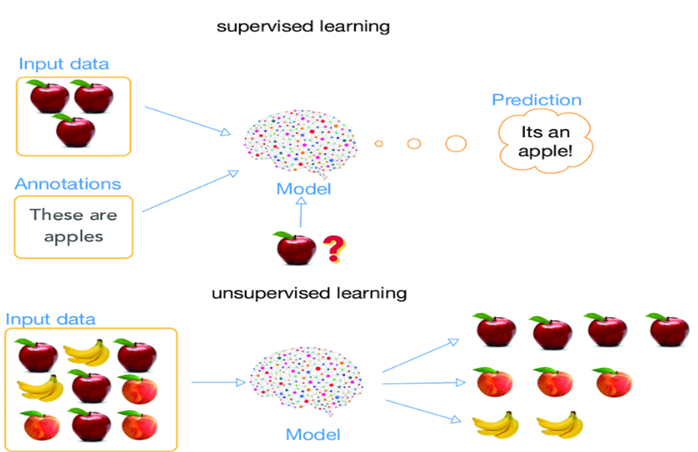
Büyük Dil Modelleri Nedir ve Kullanım Alanları Nelerdir?
Doğal dil işleme, dil ile ilgili görevleri yerine getirmek için kullanılan yapay zeka alanıdır ve halihazırda hayatımızda yer almaktadır. Bu sistemler, belli bir düzeyde istenilen görevleri yerine getirebiliyor ancak yeterince iyi değillerdi. 2017 yılında Google Research ekibi tarafından, dil tercümesini daha iyi hale getirmek amacıyla yayımlanan “Attention is All You Need” makalesi, bu görevleri çok daha iyi şekilde yapabilen büyük dil modellerinin gelişimi için kapı araladı. Daha sonra, artan işlem gücü ve metinsel verilerle birlikte, yine Google tarafından geliştirilen ve Attention mekanizmasını kullanan BERT, yüksek parametre sayılarına sahip ve denetimsiz ön eğitimden geçmiş OpenAI’ın GPT modelleri bu gelişimi sürdürdü.
Büyük dil modelleri, internet, kitaplar, makaleler ve video transkriptleri gibi farklı kaynaklardan elde edilmiş metinsel verilerle eğitilmiş, çok büyük sayıda parametreye sahip olan gelişmiş derin öğrenme modelleridir. Çok farklı Doğal Dil İşleme (DDİ) görevleri üzerinde eğitilen bu gelişmiş modeller, temelde aldıkları metinsel girdiye dayanarak sıradaki kelimeyi tahmin ederler.
Büyük dil modellerinin uygulama alanları çok daha geniş bir yelpazeyi kapsar. İnsanlarla etkileşim kurma yeteneği, doğal ve anlamlı diyaloglar gerçekleştiren sohbet botlarında en belirgin şekilde kendini gösterir. Bu botlar, müşteri hizmetlerinde, eğlence amaçlı sohbetlerde, eğitim materyallerinde kullanılabilir. Büyük dil modellerini kullanarak, reklamlar, blog yazıları, sosyal medya paylaşımları gibi farklı içerik türleri oluşturmak mümkündür. Belirli bir konuda özel dil modellerini eğiterek içeriğin kalitesi, akıcılığı ve özgünlüğü artırılabilir. Metinlerde yer alan duygusal tonu (pozitif, negatif, nötr) ve anlatılan konuyu analiz eden büyük dil modelleri, müşteri memnuniyetini ölçmede, sosyal medya trendlerini takip etmede, ve hatta reklam kampanyalarının etkisini değerlendirmede kullanışlıdır.
Uzun metinlerden özetler üretilen büyük dil modelleri, önemli bilgileri içeren, orijinal metnin özünü yansıtandır. Bu özellik, akademik araştırmada, özetlerin ve raporların oluşturulmasında faydalı olarak kullanmak mümkündür. Büyük dil modelleri, programlama dillerinde kod parçaları üretme yeteneğine de sahiptir. Bu yetenek, kod yazma süreçlerini kolaylaştırabilir, hata oranlarını azaltabilir ve kodlama yeteneği olmayan kişilerin de yazılım geliştirmelerine olanak tanıyabilir.
Bunlara ek olarak farklı diller arasında çeviri yapma konusunda büyük dil modelleri oldukça başarılıdır.
Büyük dil modelleri nasıl çalışır?
Tokenizasyon
Bilgisayarlar verileri bizimle aynı şekilde algılamaz; onlar yalnızca sayıları (1 ya da 0) görür. Bu yüzden, yapay zeka modeline eğitim sırasında veya yürütme sırasında verilen metinsel verilerin sayılarla ifade edilmesi gerekir. Bu amaçla metinler önce tokenlara ayrılır. Tokenlar, büyük metinsel verilerin daha küçük ve anlamlı parçalara bölünmesidir. Bu işleme tokenizasyon denir. Örneğin OpenAI’ın kullandığı tokenizer, “ILGE yapay zeka” metnini aşağıdaki şekilde 6 farklı token’a ayırır. Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)
Bir önceki aşamada token haline getirilen veriler, bu aşamada matematiksel olarak anlamlı vektörlere dönüştürülür. Bu vektörler, yakınlık ve aralarındaki açı gibi faktörlerle kelimelerin sadece sayısal olarak ifade edilmesini sağlamakla kalmaz, aynı zamanda birbirleri arasındaki ilişkileri de temsil eder. Bu aşamalar, dil işleme alanının temel adımlarından biri olup, büyük dil modellerinden çok daha önce bu alana kazandırılmıştır. Kelimeleri vektörleştirirken, birbirleriyle olan bağlamlarının da öğrenilmesi için, cümledeki boşlukları dolduran, kelimenin çevresindeki diğer kelimeleri tahmin eden ve buna benzer görevlerle derin öğrenme teknikleri kullanılır. Bu öğrenme sayesinde semantik olarak birbirine yakın kelimeler daha yakın vektörlerde yer alırken, zıt anlamlı kelimeler ise karşıt konumlarda bulunur.
Pozisyonel Kodlama (Positional Encoding)
Büyük dil modelleri, kelime dizilerini işlerken sadece kelimelerin anlamlarını değil, aynı zamanda kelimelerin sıralarını da dikkate almalıdır. Fakat kelime vektörleri (embeddings) kendi başlarına sıra bilgisini taşımazlar. Örneğin, "Ali okula gitti." ve "Gitti okula Ali." cümleleri aynı kelimeleri içermesine rağmen farklı cümlelerdir. Bu nedenle, modellerin bu tür sıra farklılıklarını anlaması için pozisyonel kodlama kullanılır.

Şekil-1 Örnek bir pozisyonel kodlama
Pozisyonel kodlama, her tokenın pozisyonunu matematiksel bir vektörle ifade ederek, tokenın cümle içindeki sıralı yerini belirginleştirir. Bu işlem genellikle sinüs ve kosinüs fonksiyonları kullanılarak yapılır, çünkü bu fonksiyonlar periyodik oldukları için farklı pozisyonlarda benzersiz ancak ölçeklenebilir kodlamalar sağlar.
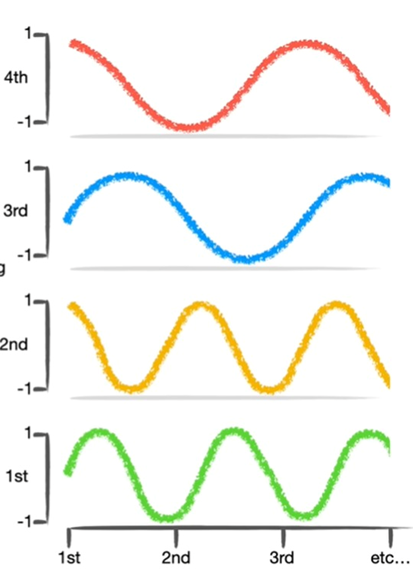
Şekil-2 Pozisyonel kodlama için sinüs/kosinüs fonksiyonları
Öz Dikkat Mekanizması (Self Attention Mekanizması)
Biz insanlar için “Pizza fırından çıktı ve onun tadı güzeldi!” cümlesinde tadı güzel olan şeyin fırın değilde pizza olduğunu anlamak kolaydır, ancak makineler için aynı şey söz konusu değildir. Self attention daha uzun dizilerin anlamlı bir şekilde işlenmesini sağlayan ve büyük dil modellerini bu kadar güçlü kılan Transformer mimarisinin yapıtaşı olan mekanizmadır. Dizi içinde bulunan vektörlerin her biri diğer vektörlerle ilişkilerini değerlendirerek, her kelimenin cümle içindeki önemini ve bağlamını belirler.
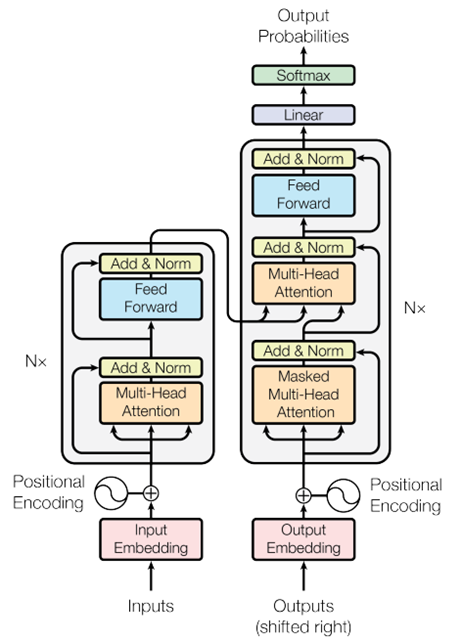
Şekil-3 Transformer model mimarisi
Öz dikkat mekanizmasında anahtar (key), değer (value) ve sorgu (query) kavramları, veriler arasındaki ilişkileri modellemek için kullanılır. Bu değerler eğitim sırasında öğrenilen bir dizi ağırlık ile vektörün çarpımı sonucu elde edilir. Bu sayede her kelime için bir sorgu vektörü oluşturulur. Bu vektör, diğer kelimelerle olan ilişkileri belirlemek için kullanılır. Daha sonra her kelime için bir anahtar vektörü üretilir. Bu anahtarlar, diğer kelimelerin sorguları ile karşılaştırılarak her kelimenin birbirine olan etkisinin derecesini belirler. Değer ise sorgu ile uyumlu anahtarlar bulunduğunda, bu anahtarlara bağlı değerler önem derecelerine göre toplanarak kelimenin yeni, güncellenmiş bir temsilini oluşturur.
Bir cümledeki her kelime için, öz dikkat mekanizması bu kelimenin diğer kelimelerle olan ilişkisini hesaplar. Her bir kelimenin sorgu vektörü, diğer tüm kelimelerin anahtar vektörleri ile bir dizi skor (dikkat skoru) hesaplamak için çarpılır. Bu skorlar softmax fonksiyonu ile normalize edilir, böylece her bir kelimenin diğer kelimeler üzerindeki etkisi bir olasılık dağılımı olarak ifade edilir.
Normalize edilmiş skorlar daha sonra ilgili değer (value) vektörleri ile çarpılır ve sonuçlar toplanarak her kelime için yeni bir vektör (dikkat çıktısı) oluşturulur. Bu yeni vektörler, kelimelerin cümle içindeki anlamını ve bağlamını daha iyi yansıtan, zenginleştirilmiş temsillerdir.
Çok Başlı Dikkat (Multi-Head Attention)
Transformer mimarisinin önemli bir parçası olan çok başlı dikkat, birden fazla dikkat başlığının bir arada kullanılması ile ortaya çıkar. Bu yapının çalışma mantığını anlamak için CNN’lerdeki filtreler düşünülebilir. Farklı filtreler görseldeki farklı özellikleri yakalar. Çok başlı dikkat’te de durum benzerdir. Farklı ağırlıklara sahip birçok dikkat başlığı (Self Attention) kullanılarak cümlenin farklı yerlerine odaklanılır. Bu başlıklar, cümlenin farklı bölümlerindeki ilişkileri öğrenir ve tespit eder.
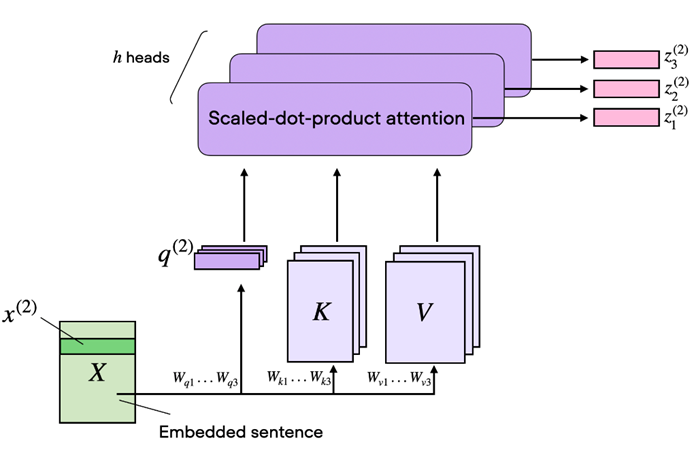
Şekil-4 Çok başlı dikkat katmanının yapısı
Maskelenmiş Çok Başlı Dikkat (Masked Multi-Head Attention)
Maskelenmiş çok başlı dikkat, dil modellemesinde özellikle önemlidir. Bu mekanizma, modelin sadece önceki kelimelere bakarak bir sonraki kelimeyi tahmin etmesini sağlar. Maskelenmiş çok başlı dikkat, gelecekteki kelimeleri maskeleyerek, modelin gelecekteki bilgilere erişimini engeller. Bunun amacı dil modeli oluştururken her adımda sadece önceki kelimeleri kullanarak tahmin yapmayı mümkün kılar. Örneğin, bir cümleyi kelime kelime üretirken modelin ilerideki kelimeleri bilmemesi gerekir ve bu mekanizma bunu sağlar.
Dikkat çıktıları elde edildikten sonra topla ve normalleştir (Add & Norm) katmanı, iki temel işlemi içerir. Artık Bağlantı (Residual Connection) girişe orijinal girdiyi ekler ve derin modellerde gradyanların daha etkili bir şekilde geri yayılmasını sağlar ve daha derin katmanların öğrenmesini kolaylaştırır. Katman Normalizasyonu (Layer Normalization) ise girdinin her bir bileşenini normalize eder. Sonuç olarak modelin daha hızlı ve kararlı öğrenmesini sağlar.
Topla ve normalleştir katmanının ardından, ileri besleme (Feed Forward) katmanı devreye girer. İleri besleme katmanı, her pozisyon için bağımsız olarak çalışan tam bağlantılı bir sinir ağıdır ve genellikle iki lineer dönüşümden ve bir aktivasyon fonksiyonundan oluşur. Bu katman, modelin daha karmaşık ve soyut temsil seviyeleri öğrenmesini sağlar. İleri besleme katmanından elde edilen çıktı, tekrar topla ve normalleştir katmanına gönderilir ve ardından doğrusal katmanına geçer.
Son olarak, Lineer ve Softmax katmanları uygulanır. Lineer katmanı, modelin çıktısını sınıflandırma için uygun bir forma dönüştürür. Softmax katmanı ise modelin her bir olasılıkla ilgili tahminlerini normalize eder ve olasılık dağılımı elde edilir. Bu aşamaların sonunda, büyük dil modeli, girdiye dayalı olarak en olası kelime veya kelime dizisini üretmiş olur.
Büyük Dil Modelini İnce Ayarlama (Fine-Tuning)
Bir projeye başlarken önce problemimizi belirleriz. Problemi iyi anladıktan sonra, çözüm için en iyi yöntemin büyük dil modelleri olduğu kanısına varabiliriz. Bir büyük dil modelini sıfırdan üretip onu eğitecek kadar çok veriye ve hesaplama gücüne ulaşmanın ne kadar zor olduğunun farkındayız. Bu yüzden ilk yapmamız gereken şey, açık kaynaklı veya kapalı kaynak dil modellerini problemimiz üzerinde test etmek olacaktır. Açık kaynaklı bir modeli kendi sistemimizde veya bir bulut servisinde çalıştırabiliriz. Kapalı kaynak sistemlerini ise kullanım bedeli ödeyerek projelerimize dahil ederiz. İnce ayar düşünmeden önce sistem mesajını optimize etmemiz gerekir; buna prompt mühendisliği denir. Eğer bu durum sonrasında hala istediğimiz sonuçlardan uzak isek, halihazırda ince ayar yapılmış büyük dil modellerini arayıp denemeliyiz. Örnek olarak bu tür modellere Huggingface, Kaggle vb sitelerden ulaşabiliriz. Tüm bu aşamalardan sonra hala olumlu sonuç yoksa, problemimize uygun ince ayar yöntemini seçer, uygun veriyi toplar ve ince ayar için eğitime başlarız. Güncel olarak LoRA ve QLoRA ile ince ayar yapmak performans ve kolaylık açısından çok popülerdir.
LoRA ile İnce Ayar
LoRA ile ince ayarın nasıl yapıldığı hakkında görece olarak basit olan ve eğitimi daha kolay olan bir model üzerinde bir Kaggle kullanıcısının paylaştığı kodu inceleyebilirsiniz.
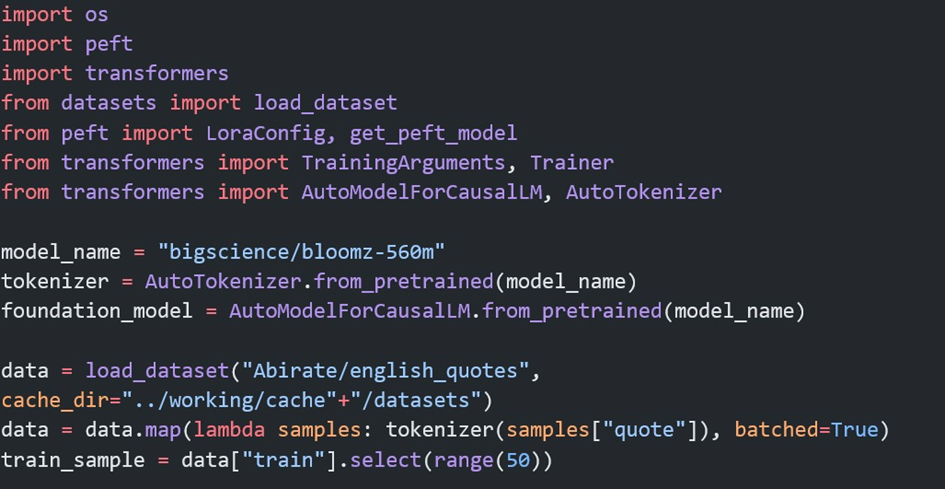
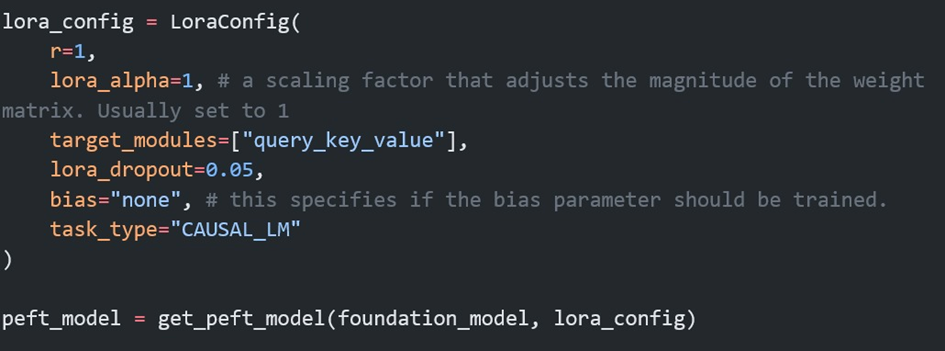
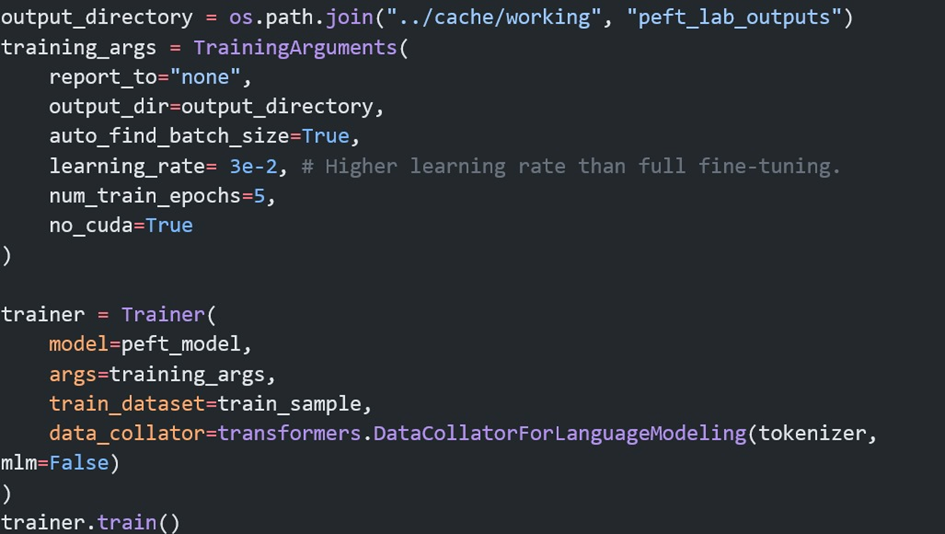
Sonuç:
Büyük dil modelleri, Doğal Dil İşleme alanında çığır açan yapay zeka sistemleridir. Bu modeller, geniş veri kümeleri üzerinde eğitilerek, insan benzeri metin oluşturma, çeviri, özetleme ve daha birçok dil tabanlı görevleri yerine getirebilir. BDM'lerin temel yapı taşları tokenizasyon, kelime gömmeleri, pozisyonel kodlama ve öz dikkat mekanizması gibi tekniklerdir. Özellikle 2017 yılında Google tarafından geliştirilen Transformer mimarisi, bu modellerin performansında büyük bir sıçrama sağlamıştır. Transformer'ların çok başlı dikkat mekanizması, dilin karmaşık yapısını anlamada ve metinlerin bağlamını doğru bir şekilde işlemede kritik bir rol oynar.
BDM'ler, müşteri hizmetlerinden, içerik oluşturma ve programlamaya kadar geniş bir yelpazede kullanılır. İnce ayar (fine-tuning) teknikleri, bu modellerin belirli görevler için daha uygun hale getirilmesini sağlar. LoRA (Low-Rank Adaptation) gibi yöntemler, mevcut modellerin ince ayar performanslarını arttırarak modellerin verimliliğine katkı vererek daha spesifik görevlerde kullanılmalarını sağlar.
Sonuç olarak, büyük dil modelleri, DDİ'nin birçok alanında devrim niteliğinde ilerlemeler sağlamakta ve gelecekte daha geniş ve yenilikçi uygulama alanlarına zemin hazırlamaktadır. Bu modellerin gelişimi ve uygulanabilirliği, dil işleme görevlerinde insan benzeri performansa ulaşmayı mümkün kılmaktadır.
Referanslar
1- A. Vaswani et al., "Attention is all you need," 2017
2- Raschka, S. (2023, February 9). Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch.
3- Abdin, A. (2023). How to Fine-tune LLMs with LoRA. https://www.kaggle.com/code/aliabdin1/how-to-finetune-llms-with-lora
4- StatQuest with Josh Starmer, Transformer Neural Networks, ChatGPT's foundation, Clearly Explained


.png)






.png)
.png)




 SMEMA Nedir?
SMEMA Nedir?.png)
.png)