Büyük Dil Modelleri (BDM) günümüzün en önemli teknolojilerinden biridir ve isminde de yer aldığı gibi gerçekten büyüklerdir. Ancak bu onların kusursuz olduğu anlamına gelmez. Bazen onlara sorduğunuz sorulara verdikleri yanıtlar ne dediklerini bilmiyormuş gibi görünür, çünkü gerçekten hiçbir şey bilmiyorlar. Büyük Dil Modellerinin tek gördüğü, istatistiksel olarak hangi kelimelerin birbiri ile daha alakalı olduğudur neyi ifade ettikleri değil. Bu da BDM’lerin en önemli sorunlarından biri olan halüsinasyona sebep olur.
Bir diğer sorun ise bir Büyük Dil Modeli eğitildikten kısa bir süre sonra bile güncelliğini yitirir. Her an yaşanan yeni bir olay veya yeni bir keşif sonrasında onları tekrar eğitemeyiz. Çünkü bu çok maaliyetli ve verimsiz bir yaklaşımdır. Yani adeta zamanda donup kalmış hem de sanki bir kapalı kutu gibidirler. Verdikleri bilgiyi nereden elde ettiklerini de zaten bilemeyiz. Bir kişiye güneş sistemimizde en çok uydusu olan gezegenin hangisi olduğunu sorsak ve bize yanıt olarak dese ki 10 sene önce çocukken bir dergide Jüpiterin 88 uydusu olduğunu gördüm vermesi gibidir. Bu bilginin kaynağını bilmiyoruz ve güncel değil.
Ve eğer Büyük Dil Modelimizin belirli bir alana özgü şekilde çok yüksek doğrulukla ve verimlilikle çalışmasını istersek, halihazırda bulunan BMD’ler bu isteğimizi karşılamaz. Çünkü genel amaçlı eğitilmişlerdir. Buna çözüm olarak onlara bu alana özgü veri setleri ile ince ayar (fine tuning) yapabiliriz.
Bu yöntem ne kadar maaliyetli bir iş olsada o alana özgü genel bakış açısını Büyük Dil Modeline sağlar. Ancak bu modellerin öncesinde çok büyük veri setleri ile eğitildiğini düşünürsek, ince ayar için kullandığımız veri seti onu bir görevde mükemmel yapmak için yeterli olmaz. Tüm bu problemleri azaltabilmek veya çözebilemek için 2020 yılında Facebook Research yaptığı araştırma sonucu almayla artırılmış üretim (RAG) yöntemini tanıttı. Bu yöntem ince ayar yapmaya göre oldukça düşük maaliyete sahiptir ve uygulaması da daha kolaydır. RAG’in birden çok yöntemi vardır ancak hepsinde genel mantık aynıdır. Girilen isteme göre bir sorgu elde edilir. Daha sonrada bu sorguyu kullanarak önceden belirlenmiş bilgi kaynaklarından en alakalı veriler getirilir. Bu getirilen veriler istemle birleşitirilerek Büyük Dil Modeline sunulur. Bu ise BDM’in güncel veya bağlama en yakın bilgiye sahip olmasını sağlar.
Sorgu (Query) ve İstem (Prompt) Nedir?
Yazının devamında bu iki kavramı oldukça sık göreceğiz. Bu yüzden başlangıçta ayrımı yapmamız iyi olacaktır. Kullanıcı Büyük Dil Modelinden bir yanıt almak için ona bazı sorular sormalı veya talimatlar girmelidir. Bu girdinin bütününe istem denir. Küçük bir kelime veya harf değişikliğinde bile yanıt tamamen farklı gelebilir. En uygun promptu bulma pratiğine istem mühendisliği (prompt engineering) denir. Sorgu ise sisteme RAG’i dahil ettiğimiz zaman devreye girer. Bu durumda Büyük Dil Modeli’ne kendi verdiğimiz istem dışında bir bağlam kazandırmak isteriz. Bu bağlam cevap beklenen konuda BDM’in sahip olmadığı güncel bir veri olabilir veya şirkete özel veriler olabilir. Belki binlerce farklı bilgi kaynağı arasından en alakalı verileri getirip prompta eklemek isteriz. Bu durumda bilgi kaynaklarını farklı algoritmalar ile taramak için bir sorgu inşa ederiz. Bu bazı durumlarda istem ile doğrudan aynı olabilir.
RAG Nasıl Çalışır?
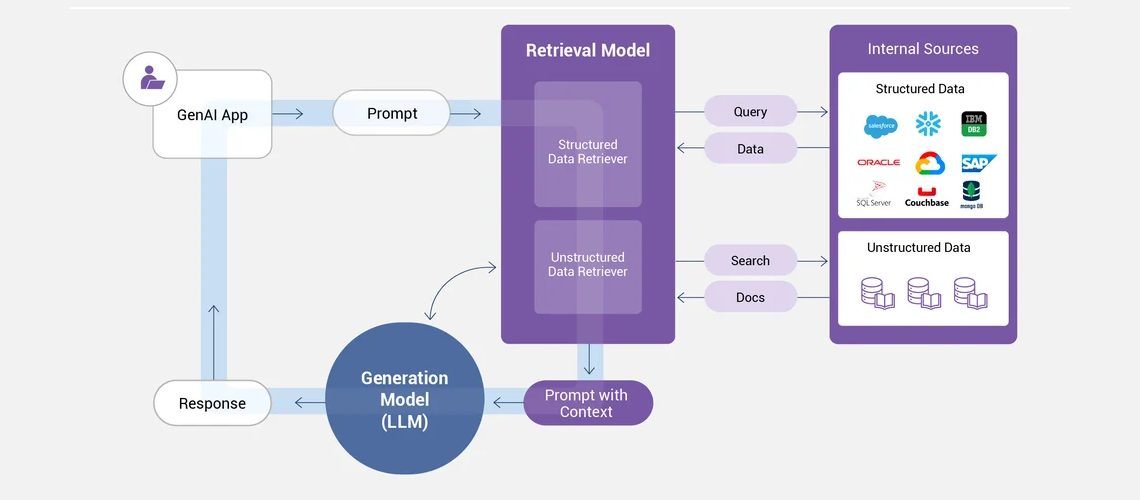
Almayla artırılmış üretim sistemi daha küçük bir çok modül olarak tanımlanabilsede temelde iki ana aşaması vardır. Birincisi; elde etme aşaması (Retrieval phase) ikinci aşama ise üretim aşamasıdır (Generation phase). İlk aşamada daha önce inşa ettiğimiz sorguyu kullanarak tek veya birden fazla bilgi kaynağı arasından sorgu (query) ile semantik olarak veya matematiksel olarak en benzer olanlarını bulur ve getirir. Bu bilgi kaynakları web araması sonuçları, şirket dökümanları veya bir veritabanı olabilir.
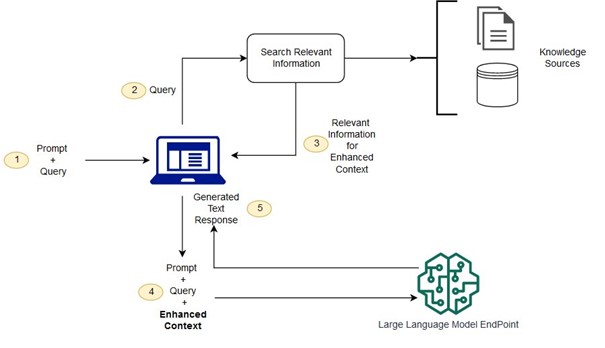
Şekil-1: Genel bir RAG Mimarisi
İkinci aşamaya üretim aşaması denmesinin nedeni, ilk aşamada elde ettiğimiz bağlamı veya bağlamları belirlenmiş bir formata göre isteme dahil ederiz. Bu üretilmiş yeni istem Büyük Dil Modeline verilir. Ve artık Büyük Dil Modeli bağlama bağlı kalarak daha tutarlı ve güncel bilgiler üretir.
RAG Aşamaları
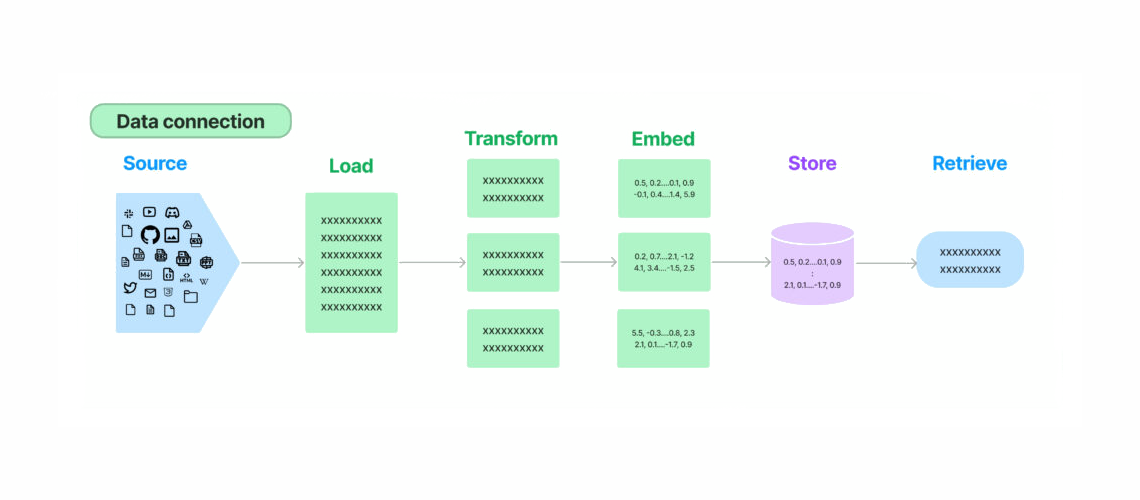
Bir RAG sistemi bir önceki başlıkta belirttiğim gibi iki temel modülün altında daha küçük alt modüllerden oluşur bunlar; sorgu oluşturma, sorgu dönüştürme, yönlendirme, indexleme, elde etme ve üretim modülleridir. Bu modüllere sırasıyla kısaca değineceğim.
.png)
Şekil-2: RAG aşamaları diyagramı
Sorgu Oluşturma (Query Construction)
Almayla artırılmış üretim sistemlerinde ilk aşama sorgu oluşturmadır. İnsan tarafından oluşturulan istemden elde edilecek olan doğal dildeki sorgu, farklı veri kaynaklarının anlayabileceği bir formata dönüştürülür. Bu SQL tabanlı veritabanları için SQL sorguları veya vektör veritabanlarında kelime gömmeleri olabilir. Bu bölüm önemlidir çünkü bilgiyi veritabanından en optimum şekilde elde etmek için sorgunun doğru yorumlandığından emin olmamız gerekir.
Sorgu Dönüştürme (Query Translation)
Sorgu dönüştürme aşaması, doğal dildeki bir sorgunun, daha anlaşılır hale getirilmesi veya daha küçük, daha spesifik parçalara bölünmesi sürecini kapsar. Bu aşama, temel olarak iki önemli adım içerir. İlk adım, Sorgu Ayrıştırma (Query Decomposition) olarak bilinir ve burada orijinal sorgu, alt sorgulara ayrıştırılır veya yeniden formüle edilir. Bu sayede, sorgunun daha karmaşık ve çok yönlü yapısı, daha küçük ve yönetilebilir bileşenlere ayrılmış olur. Bu işlem sırasında kullanılan teknikler arasında Multi-query, Step-back ve RAG-Fusion gibi yöntemler bulunur.
İkinci adım ise Sahte Belgeler (Pseudo-documents) oluşturulmasıdır. Bu süreçte, sorguya yanıt olarak, olası cevapları temsil eden hipotez belgeleri oluşturulur. Bu belgeler, gerçekte var olmayan, ancak potansiyel olarak ilgili bilgileri içeren dokümanlar gibi düşünülebilir. Burada kullanılan HyDE yöntemi, bu tür belgelerin oluşturulmasını sağlar. Sonuç olarak, Sorgu Dönüşümü aşaması, bir sorguyu daha etkili bir şekilde işleyebilmek ve nihayetinde doğru cevabı bulabilmek için çeşitli dönüşüm ve ayrıştırma işlemlerini içerir.
Sorgu Oluşturma (Query Generation): Kullanıcının girdiği sorgudan, çeşitli alt sorgular türetilir. Bu alt sorgular, farklı bakış açılarını yakalayarak, kullanıcının niyetini tam olarak anlamaya çalışır. Böylece sorgunun daha kapsamlı bir şekilde ele alınması sağlanır.
Alt Sorgu Getirme (Sub-query Retrieval): Her alt sorgu için büyük veri setlerinden ve bilgi havuzlarından ilgili bilgiler toplanır. Bu adım, kapsamlı ve derinlemesine arama sonuçları elde etmek amacıyla yapılır.
Karşılıklı Sıralama Birleşimi (Reciprocal Rank Fusion): Getirilen dokümanlar, Reciprocal Rank Fusion (RRF) yöntemi kullanılarak birleştirilir. Bu yöntem, dokümanların sıralarını birleştirerek en alakalı ve kapsamlı sonuçları önceliklendirir, böylece en iyi yanıtları elde etmemizi sağlar.
Yönlendirme (Routing)
Yönlendirme (Routing) aşaması birden fazla veri kaynağı varken, gelen sorgunun hangi veritabanına veya bilgi kaynağına yönlendirileceğine karar verilmesini sağlar. Bu mantıksal yönlendirme ve anlamsal yönlendirme olarak çalışma şekline göre iki farklı şekilde yapılabilir.
.png)
Şekil-3: Yönlendirme örneği
Mantıksal Yönlendirme (Logical Routing): Bu yöntemde sorgunun yapısına bağlı olarak birden fazla veri kaynağı arasından hangisinin kullanılacağına mantıklı bir değerlendirme sonucu karar verilmesini ifade eder. Bu aşamada arzu edilirse bu seçme işlemi için de Büyük Dil Modeli kullanılabilir.
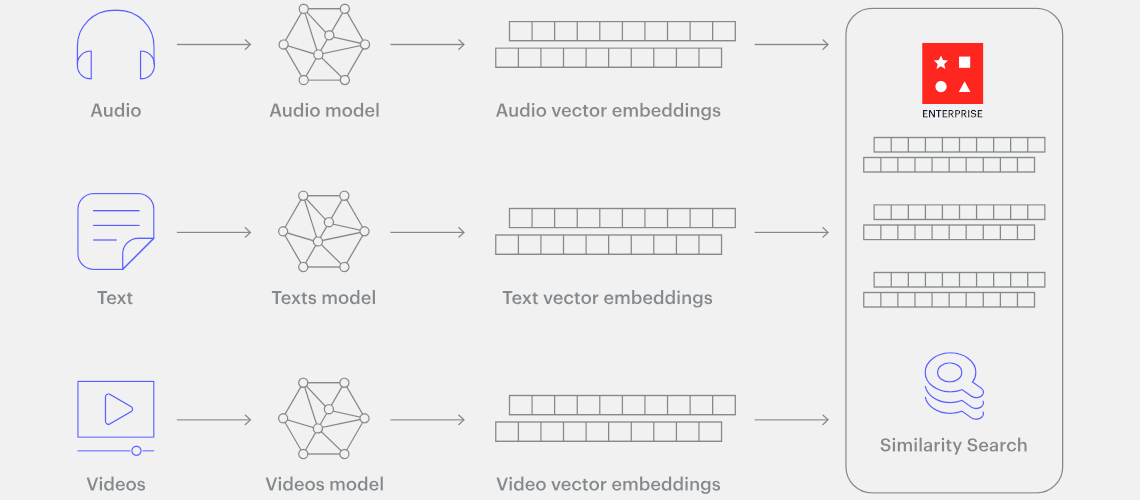
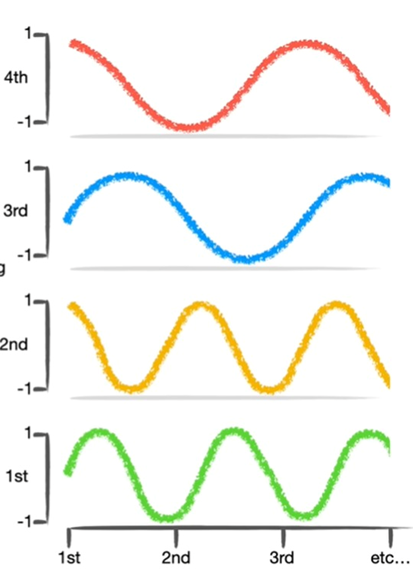
Anlamsal Yönlendirme (Semantic Routing): Bu yönlendirme metodunda ise mantıksal değil üretilmiş sorgunun anlamına göre çoklu veri kaynaklarından gelecek yanıtlar arasından hangisinin daha uygun olabileceğine karar verilmesidir. Bunu elde etmek için ise kelime gömmeleri (word embeddings) yani bir uzayda yön ve konumsal olarak anlam ifade eden vektörler kullanılabilir.
Kalan diğer aşamalar için girişte yaptığım tanımlama ile açıklamıştım. Kısaca özetlemek gerekirse Getirme (Retrieval) aşaması veri kaynağı seçildikten sonra ilgili dökümanları alıp listelemeyi içeriyor. Bu süreçte farklı sıralama (ranking) algoritmaları çalışabilir. İndeksleme (Indexing) aşamasında veriler önce parçalara (chunk) ayrılıp düzenleniyor, farklı formatlarda saklanıyor, alanına özel gömme teknikleri ile işleniyor ve doküman özetleri bir ağaç yapısında farklı seviyelere göre gruplandırılıyor. Son aşama olan üretimde (generation) istem için en uygun cevabı üretmek üzere çekilen dokümanlar ve yeniden yazılmış istemler kullanılarak yanıt elde edilir.
Reciprocal Rank Fusion (RRF)
Reciprocal Rank Fusion (RRF), birden fazla arama sonucunu birleştirerek tek bir sıralı sonuç kümesi oluşturmak için kullanılan bir algoritmadır. RRF, her bir arama sonucunun sıralamasına ters sıralama puanı atayarak çalışır. Bu puanlar daha sonra toplanır ve sonuçlar bu birleşik puanlara göre sıralanır. Birden fazla sorgunun paralel olarak çalıştırıldığı durumlarda, özellikle karma arama ve birden fazla vektör sorgusu gibi senaryolarda kullanılır. RRF, her bir sonuç listesindeki öğelerin orijinal sıralamasını dikkate alarak, birden fazla listede üst sıralarda yer alan öğelere daha yüksek önem verir. Bu, son sıralamanın genel kalitesini ve güvenilirliğini artırır. Şöyle bir örnek verilebilir: İnternette aynı şeyi aradığınızda, farklı arama motorları veya yöntemleri size farklı sıralamalarda sonuçlar sunar. RRF, bu farklı sıralamalardaki sonuçları alır ve en üstte olanları daha önemli kabul ederek, hepsini birleştirir. Böylece, en alakalı sonuçlar yeni oluşturulan listenin en başında yer alır. Bu yöntem, farklı kaynaklardan gelen sonuçları tek bir listede en iyi şekilde sıralamak için kullanılır.
LangChain Kullanarak Basit RAG Oluşturmak
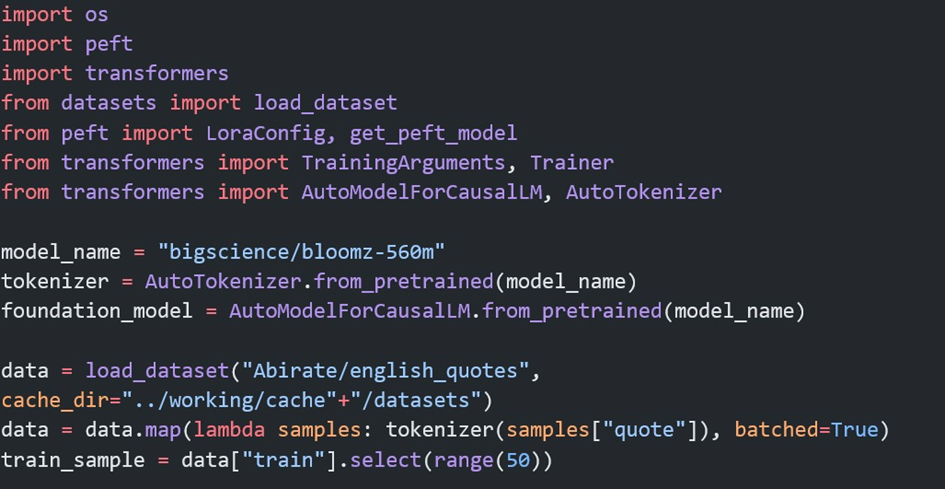
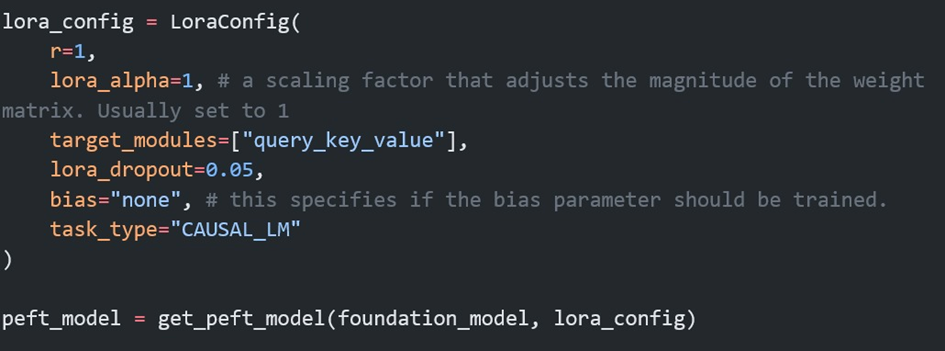
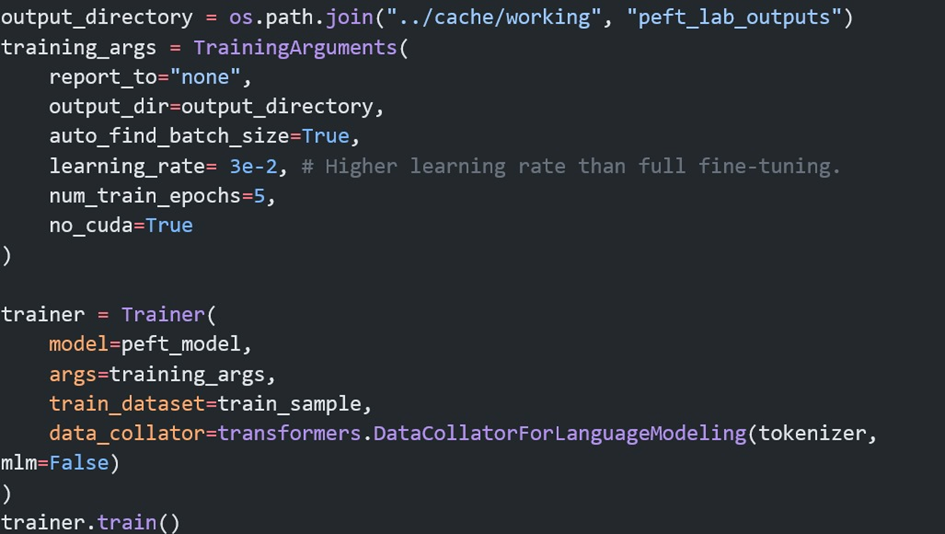
LangChain, Büyük Dil Modelleri ve diğer AI araçlarını kullanarak çeşitli görevler gerçekleştirmek için bir zincir veya akış oluşturmanıza olanak tanıyan bir araçtır. Özellikle, doğal dil işlemi ve metin üretimi gibi görevlerde, büyük dil modellerini daha verimli ve hedefe yönelik kullanmak için araçlar sunar. LangChain, veri sorgulama, belge arama, özetleme ve karar destek sistemleri gibi uygulamalarda kullanılır ve genellikle BDM’leri daha karmaşık iş akışlarına entegre etmek için kullanılır. Basitten karmaşığa bir çok sistem için kullanılabilir. RAG sistemi oluşturmak için LangChain dökümantasyonundan basitçe bir kod örneği aşağıya ekledim.
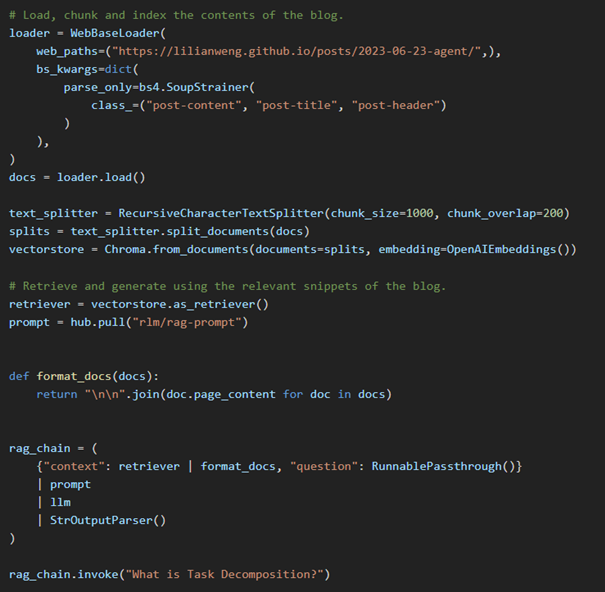
Şekil-4: LangChain ile RAG oluşturma kodu
Sonuç
BDM'lerin zamanla güncelliğini yitirmesi ve halüsinasyon gibi sorunlara yol açabilmesi, bu modellerin pratik uygulamalarda karşılaştığı başlıca sorunlar arasındadır. RAG, bu sorunlara çözüm sunmak amacıyla ortaya çıkmış bir yöntemdir ve ince ayar yapmaya kıyasla daha düşük maliyetli bir alternatif olarak öne çıkmaktadır. RAG'in işleyişi, çeşitli aşamalar ve modüller üzerinden detaylı bir şekilde açıklanmış, özellikle sorgu oluşturma, dönüştürme ve üretim aşamaları üzerinde durulmuştur. LangChain gibi araçlar sayesinde, RAG sistemleri basit bir şekilde oluşturulabilir ve entegre edilebilir. Bu çalışmalar, BDM'lerin daha verimli ve doğru bir şekilde kullanılabilmesi için önemli bir adımı temsil etmektedir.
Referanslar
1- Amazon Web Services. What is RAG (Retrieval-Augmented Generation?)
2- Yöndem, D. Retrieval Augmented Generation'a Giriş [Video].
3- IBM Research. What is retrieval-augmented generation?
4- A Comprehensive Guide to RAG Implementations. NoCode.ai Newsletter.
5- Singh, S. Mastering RAG: Advanced Methods to Enhance Retrieval-Augmented Generation.
6- Build a Retrieval Augmented Generation (RAG) App, LangChain Dökümantasyonu
7- Relevance scoring in hybrid search using Reciprocal Rank Fusion (RRF), Microsoft


.png)




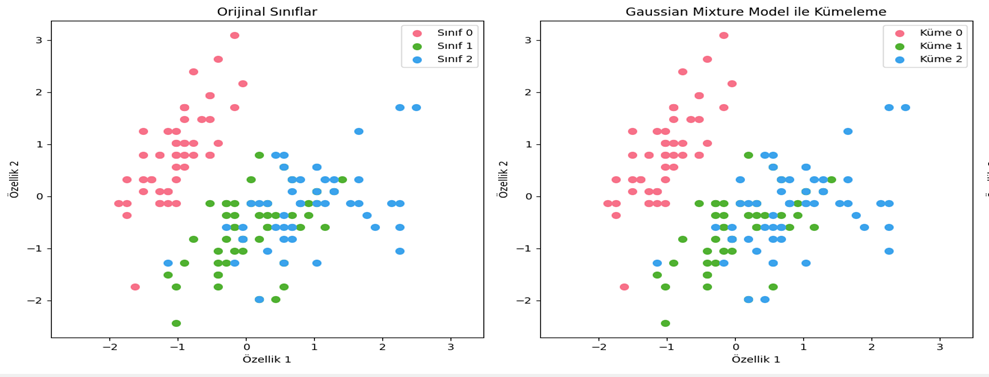
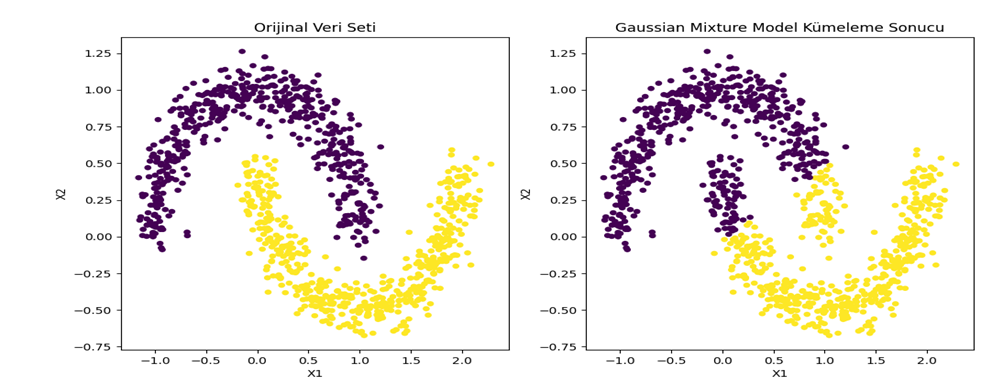

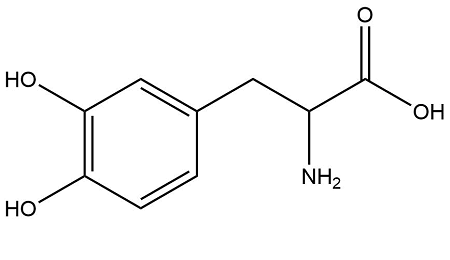



 Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)


 SMEMA Nedir?
SMEMA Nedir?.png)
.png)