
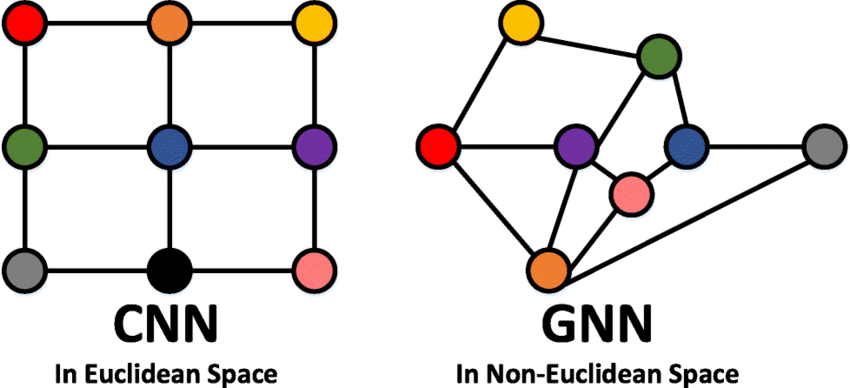
Kümeleme yöntemleri, etiketlenmemiş verileri belirli metriklere dayanarak gruplandırmak ve ayırmak için kullanılan bir makine öğrenmesi yaklaşımıdır. İlgili yöntemler, çalışma prensiplerine veya kullandıkları benzerlik ölçüm tekniklerine göre birçok farklı türe sahiptir. Peki, etiketli ve etiketsiz veri kavramları neyi ifade eder?
• Etiketli Veriler: Bir yapay zeka modelinin elma ve muzu ayırt etmesini istediğimizi düşünelim. Elma ve muz resimlerini eğitim verisi olarak modelimize verirken, her bir resmin hangi meyveye ait olduğunu açıkça belirtiriz. Yani, resimler "elma" veya "muz" olarak etiketlenmiştir. Ayrıca, elma ve muzun özelliklerini (örneğin rengi, boyutu, şekli vb.) sağlayarak, özelliklerin hangi nesneye ait olduğunu gösteririz. Böylelikle model, etiketli veriler üzerinden öğrenerek yeni gelen verileri doğru bir şekilde sınıflandırmayı öğrenir.
• Etiketsiz Veriler: Şimdi ise yapay zekaya sadece elma ve muzun özelliklerini verdiğimiz, ancak bu özelliklerin hangi meyveye ait olduğunu belirtmediğimiz bir senaryo düşünelim. Yani, elma ve muza ait özellikler mevcut, ancak hangi özelliğin elmaya, hangisinin muza ait olduğunu söylemiyoruz. Bu durumda model, verilerdeki benzerlik ve farklılıkları analiz eder. Benzer özelliklere sahip olanları aynı grupta toplayabilir.Bu süreçte kümeleme yöntemleri kullanılır ve model, verileri doğal olarak oluşan gruplara ayırır.
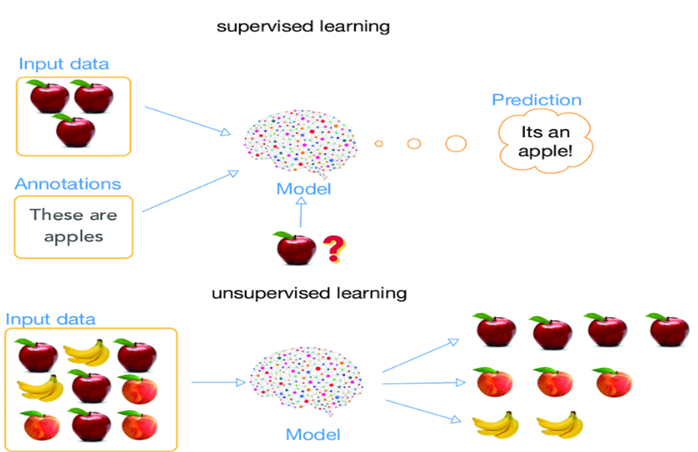
Şekil 1 - Denetimli ve denetimsiz öğrenme
Peki, yapay zeka verideki örneklerin hangi sınıfa ait olduğunu bilmeden elma ve muzu nasıl ayırt edebilir? Bu sorunun cevabına geçmeden önce, neden etiketsiz verilerle çalışmanın önemli olduğunu açıklığa kavuşturalım.
Etiketli verilerle çalışmak genellikle daha avantajlıdır çünkü modelin performansını rahatça test edebilir ve amaca uygun olarak veri veya model üzerinde manipülasyonlar yapabiliriz. Etiketli verilerde, her bir örneğin hangi sınıfa ait olduğunu bildiğimiz için modelin doğruluğunu doğrudan değerlendirebiliriz. Ancak, gerçek hayattaki problemlerimizde elimizdeki verilerin hangi sınıfa ait olduğunu her zaman bilemeyebiliriz veya bu verileri etiketlemek çok maliyetli ve zaman alıcı olabilir.
• Sosyal Medya: Kullanıcıların paylaşımları, yorumları ve etkileşimleri genellikle etiketlenmeden toplanır. Sosyal medyadan toplanan büyük veri setlerini etiketlemek çok maliyetlidir, çünkü her bir yorumu bir insanın tek tek okuması ve değerlendirmesi gerekir.
Bu nedenle, etiketsiz verilerle çalışmak zorunda kalabiliriz. Etiketsiz verilerle çalışırken, model verideki örneklerin doğal gruplarını veya kalıplarını keşfetmeye odaklanır. Kümeleme yöntemleri kullanılarak, benzer özelliklere sahip veriler aynı gruplarda toplanır. Bu sayede, yapay zeka elma ve muz gibi farklı sınıfları, sınıf etiketleri olmadan da ayırt edebilir.
Popüler Olan Kümeleme Yöntemlerine Örnekler İle Bir Bakış Atalım:
K-means Kümeleme Algoritması
• Neden Kullanılır?
- Veri Gruplama: Veri setindeki benzer öğeleri gruplamak için kullanılır, böylece veri analizi ve yorumlama kolaylaşır.
- Özellik Seçimi: Veri kümesindeki önemli özelliklerin belirlenmesine yardımcı olur.
- Görüntü İşleme: Görüntüleri benzer özelliklere göre gruplamak için kullanılır, örneğin renklerin gruplandırılması (Bkz. Şekil 2).

Şekil 2 - K-means ile segmente edilmiş görüntü
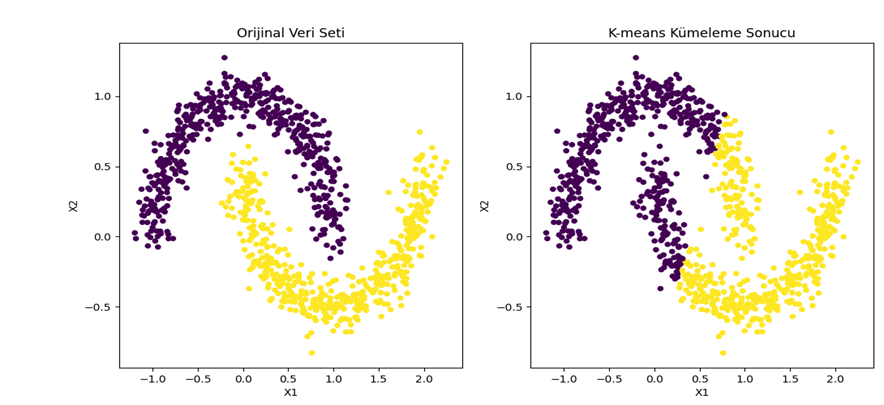
Şekil 3 - Sklearn make_moons veri seti kullanılarak k-means ile kümeleme sonucu
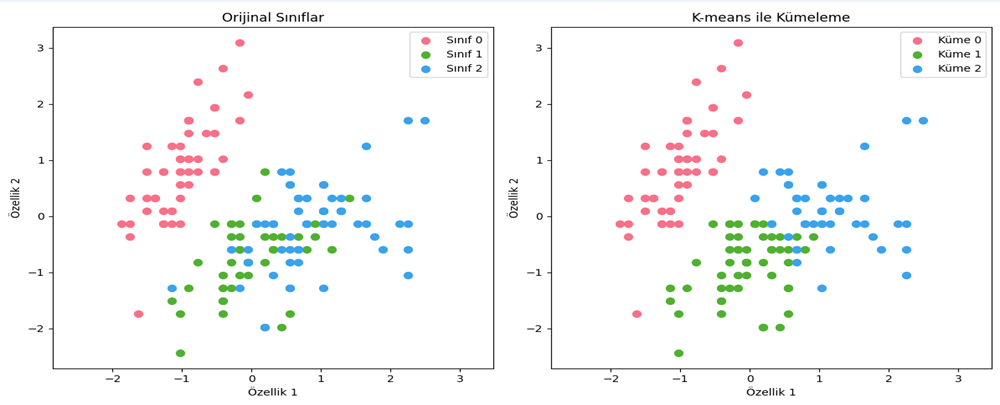
Şekil 4 - Iris veri seti kullanılarak K-means kümeleme sonucu
Şekil 3’e ve Şekil 4’e bakıldığında, K-means yönteminin kümeleri dairesel olarak hesapladığı için istenilen performansı veremediği görülmektedir.
DBSCAN Kümele Algoritması
• Neden Kullanılır?
- Yoğunluk Tabanlı Gruplama: Verilerin yoğun olduğu bölgeleri tanımlamak için kullanılır. Yoğun bölgeleri göz önünde bulundurarak veriyi gruplandırır.
- Aykırı Değerlerin Tespiti: Aykırı değerleri (gürültü) belirlemek için etkilidir; yoğun olmayan bölgelerdeki noktalar aykırı olarak kabul edilir (Bkz. Şekil 5).
- Belirgin Kümeler: Küme şekillerinin herhangi bir geometrik yapıya bağlı kalmadan belirlenmesine olanak tanır; bu da karmaşık ve düzensiz formlardaki kümeleri tespit etme yeteneği sağlar (Bkz. Şekil 6).
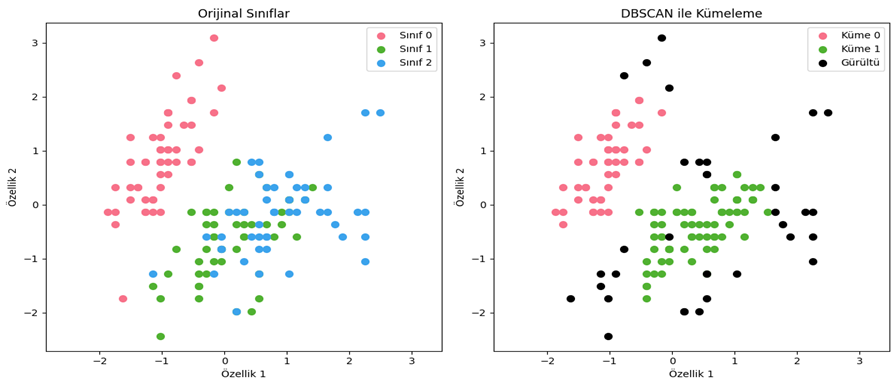
Şekil 5 - Iris veri seti DBSCAN ile kümeleme sonucu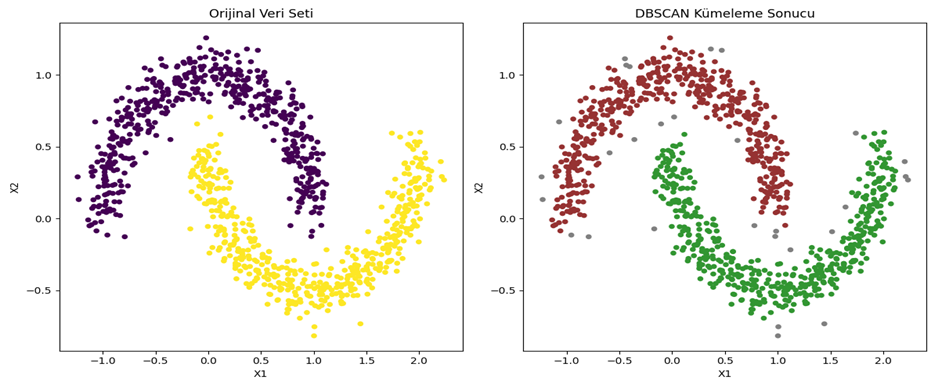
Şekil 6 - Sklearn make_moons veri seti DBSCAN kümeleme sonucu
Gaussian Mixture Model
• Neden Kullanılır?
- Karmaşık Dağılımlar: GMM, diğer kümeleme yöntemlerinin aksine temelde her küme için Gauss olasılık dağılımını kullandığı için karmaşık veri yapılarında tercih edilebilir (Bkz. Şekil 7).
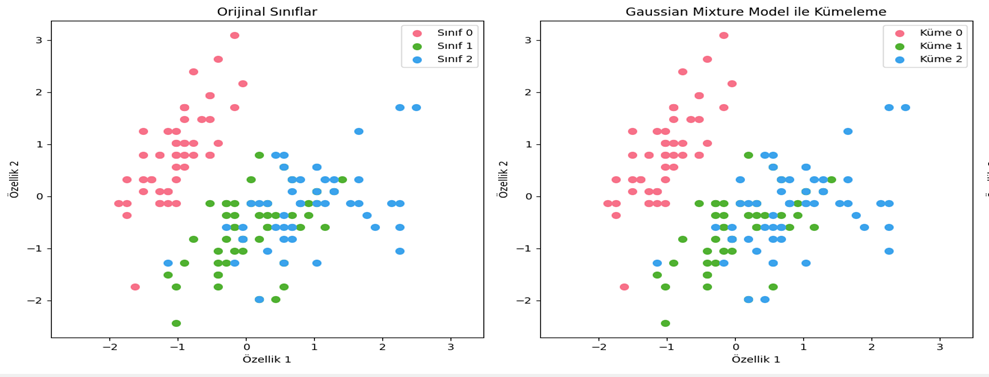
Şekil 7 - Iris veri seti GMM ile kümeleme sonucu
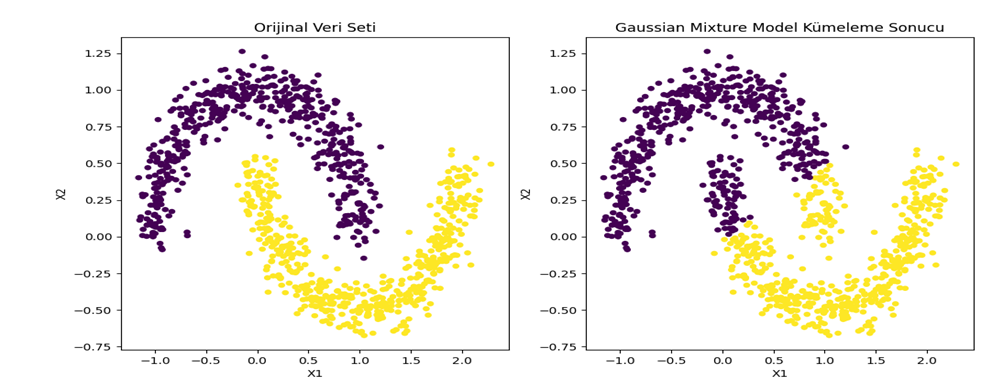
Şekil 8 - Sklearn make_moons veri seti GMM ile kümele sonucu
Kümeleme Sonuçlarının Değerlendirilmesi ve İyileştirilmesi
Kümeleme algoritmalarının performansını değerlendirmek, doğru sonuçlar elde etmek için kritik bir adımdır. Ancak kümeleme, denetimsiz bir öğrenme yöntemi olduğu için etiketlenmiş veri bulunmadığında sonuçları doğrudan ölçmek zordur. Bununla birlikte, çeşitli metrikler kullanılarak kümelerin kalitesi değerlendirilebilir:
• Silhouette Skoru: Kümedeki her bir örneğin, kendi kümesine olan uzaklığı ile diğer kümelere olan uzaklığı karşılaştırılarak hesaplanır. Skorun yüksek olması, kümelerin iyi ayrıldığını ve içlerinde sıkı bir şekilde gruplandığını gösterir.
• Davies-Bouldin Endeksi: Küme merkezleri arasındaki mesafeleri dikkate alarak kümelerin ne kadar benzer olduğunu ölçen bir metriktir. Düşük bir Davies-Bouldin skoru, iyi ayrılmış kümeler olduğunu işaret eder.
• Rand İndeksi: Verilerdeki benzerlik ve farklılıkları ölçerek kümelerin kalitesini değerlendiren bir metriktir.
Bu tür metriklerle kümeleme sonuçları değerlendirilirken, algoritmaların performansı da optimizasyon ile iyileştirilebilir. Örneğin, hiperparametre ayarı veya boyut azaltma teknikleri kullanılarak kümeleme algoritmalarının çıktıları iyileştirilebilir. Bu süreçte, algoritmaya verilen parametreler ve veri özellikleri üzerinde yapılan düzenlemeler, daha doğru ve anlamlı gruplandırmalar elde edilmesine yardımcı olabilir.
Kümeleme ile Aykırı Değerlerin Tespiti
Kümeleme algoritmaları, sadece benzer verileri bir araya getirmekle kalmaz, aynı zamanda aykırı değerleri (outliers) tespit etmek için de kullanılabilir. DBSCAN gibi yoğunluk tabanlı algoritmalar, özellikle bu konuda etkilidir. Yoğun veri noktalarının oluşturduğu kümeler dışında kalan noktalar, aykırı değerler olarak sınıflandırılabilir. Bu aykırı değerler genellikle veri setinde doğal olmayan, yanlış ölçülmüş ya da ekstrem olayları temsil eden verilerdir. Aykırı değerlerin tespiti, birçok alanda önemli bir rol oynar:
• Finans: Dolandırıcılık tespitinde, normal işlem kümelerinden sapmalar gösteren aykırı işlemler tespit edilebilir.
• Sağlık: Hastaların normal sağlık göstergeleri arasından, anormal ve riskli durumlar aykırı değer olarak tespit edilebilir.
• Endüstriyel Sensör Verileri: Üretim hatlarında sensörler tarafından kaydedilen verilerde, cihazlardaki arızaları ya da hatalı ölçümleri bulmak için aykırı değerler incelenir.
Kümeleme algoritmaları, farklı sektörlerde ve uygulama alanlarında yaygın olarak kullanılmaktadır. Örneğin, pazarlama alanında şirketler, müşterilerini davranışlarına ve demografik özelliklerine göre segmente etmek için kümeleme algoritmalarına başvururlar. Bu şekilde, hedef kitleyi daha iyi anlayarak pazarlama stratejileri geliştirir ve müşteri memnuniyetini artırırlar. Biyoinformatik alanında ise kümeleme algoritmaları, genetik veri analizlerinde büyük bir rol oynamaktadır. Genom verilerinin kümelenmesi, genler ve proteinler arasındaki ilişkilerin keşfedilmesine olanak tanır ve biyolojik süreçlerin daha iyi anlaşılmasını sağlar.
Görüntü işleme alanında da kümeleme yöntemleri sıkça kullanılır. Özellikle K-means algoritması, görüntülerin segmente edilmesi ve renk kümelerinin ayrıştırılması gibi işlemlerde yaygın bir şekilde tercih edilir. Sosyal medya analizi ise bir diğer önemli uygulama alanıdır. Sosyal medyadan elde edilen büyük veri yığınları, kullanıcıların davranışlarını incelemek, trendleri belirlemek ve kişiselleştirilmiş içerik önerileri oluşturmak için kümeleme algoritmaları ile analiz edilir. Tüm bu örnekler, kümeleme algoritmalarının veri analizinde önemli bir rol oynadığını ve geniş bir yelpazede uygulama alanına sahip olduğunu göstermektedir.
Sonuç
Yapay zekayı güncel hayatta kullanmak istediğimizde karşımıza bazı problemler çıkmaktadır:
• Verilerin etiketsiz olması: Verileri etiketlemeye çalışırken genellikle bir uzmanın yardımına ihtiyaç duyulur. Ancak, alanında uzman bir kişi bile verileri %100 doğru şekilde etiketleyemeyebilir.
• Veri miktarının çok büyük ve karmaşık olması: Büyük boyutlu ve karmaşık verilerle çalışmak, işlemleri zorlaştırır ve daha fazla zaman ve kaynak gerektirir.
Bu sebeplerden dolayı, denetimsiz öğrenme yöntemleri güncel hayat problemlerinin çözümünde önemli bir rol oynamaktadır. Bu yazıda, denetimsiz öğrenme yöntemlerinden biri olan kümeleme yöntemleri kısaca ele alınmıştır. K-means, DBSCAN ve GMM (Gaussian Mixture Model) gibi yöntemlerin yanı sıra birçok farklı kümeleme tekniği bulunmaktadır. Karşılaşılan probleme göre, bu yöntemlerin avantaj ve dezavantajları değerlendirilerek en uygun olanı seçilmelidir. Basit ama etkili olan kümeleme yöntemleri, günümüzde bile temel problemleri çözme konusunda geliştiricilere yardımcı olmaktadır.
Referanslar
https://www.researchgate.net/figure/Supervised-learning-and-unsupervised-learning-Supervised-learning-uses-annotation_fig1_329533120
https://www.freecodecamp.org/news/8-clustering-algorithms-in-machine-learning-that-all-data-scientists-should-know/
https://www.geeksforgeeks.org/clustering-based-approaches-for-outlier-detection-in-data-mining/





.png)
.png)


 Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)


 SMEMA Nedir?
SMEMA Nedir?.png)
.png)