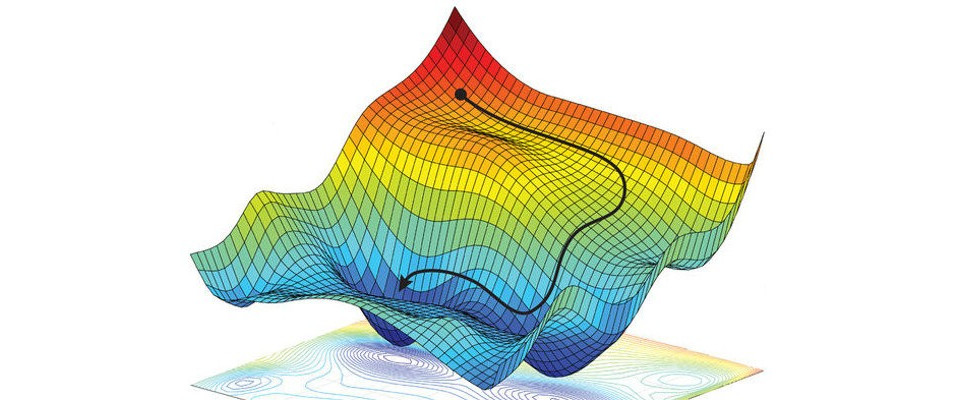


Yapay zeka alanında sürekli gelişen bir teknik olan, Pekiştirmeli Öğrenme (PO) güçlü bir etki yaratıyor ve otonom sistemler, robotlar, oyun oynama ve ötesinde çeşitli alanlarda çığır açan gelişmelere öncülük ediyor. Makine öğrenmesine kök salmış olan Pekiştirmeli Öğrenme, zeki bir ajanın çevre ile etkileşimde bulunarak, geri bildirimleri ödüller veya cezalar şeklinde alarak kararlar almaya yönelik dinamik bir yaklaşımı temsil eder. Bu etkileşimli süreç, ajanın karar alma yeteneklerini zaman içinde iteratif bir şekilde geliştirmesine olanak tanır, böylece zeki, adaptif sistemlerin alanında benzersiz ilerlemelere yol açar. Bu karakteristik davranış, temelde insan doğasının temel yönlerine benzerlik göstermektedir. İnsan, fayda sağlamak ve potansiyel zararlardan kaçınmak istemektedir. Bu karar çatışması, geri bildirim sağlayan unsuru oluşturur.
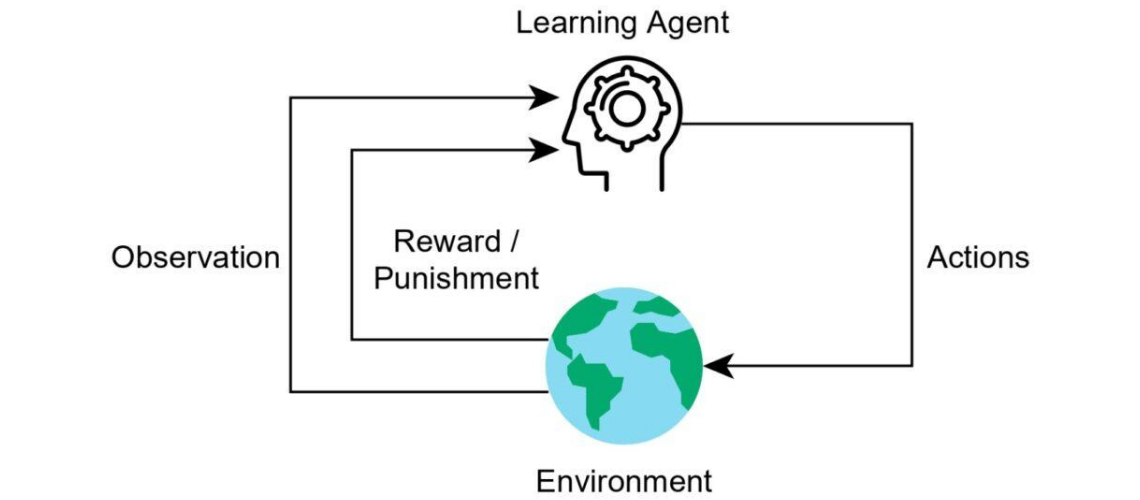
Pekiştirmeli Öğrenme, öğrenme sürecinde kritik bir rol oynayan benzersiz bir dizi temel bileşenle karakterizedir. Temelde, pekiştirmeli öğrenmede kararlar veren ajan adında bir öğe ve kararların gerekli olduğu bir bağlam alanı olan bir çevre yer almaktadır. Ajan, mevcut durumu algılayarak, önceden belirlenmiş stratejilere dayanarak eylemler seçerek, bu eylemleri gerçekleştirerek ve ödüller veya cezalar şeklinde geri bildirim alarak bu çevrede gezinir. Nihai amaç, zaman içinde ajanın karar alma yeteneklerini iteratif olarak geliştirerek, ödüllerin birikimi için optimize etmektir.
Bu makale, Pekiştirmeli Öğrenme'nin ayrıntılarını ortaya çıkarmak üzere bir yolculuğa çıkıyor. Temel unsurlarını, öğrenme sürecinin karmaşıklıklarını ve bu alandaki çığır açan uygulamalardaki etkisini keşfetmek amacıyla tasarlanmıştır. Pekiştirmeli öğrenme, manzarasını saran zorluklara dalmaktadır ve neyin başarılabileceğinin sınırlarını zorlayan son gelişmeleri aydınlatmaktadır. Bizi, Pekiştirmeli öğrenme tekniğinin temellerini parçalara ayırmaya, uygulamalarını analiz etmeye, zorluklarıyla yüzleşmeye ve yapay zeka alanındaki umut vadeden geleceğini belirlemeye davet ediyor.
Pekiştirmeli Öğrenme'nin Temel Bileşenleri:
- Ajan: Algoritmanın kalbinde, kararlar veren sanal bir varlık olan ajan bulunmaktadır.
- Çevre: Çevre, ajanın etkileşimde bulunduğu dış sistemleri temsil eder. Bu fiziksel bir alan, sanal bir simülasyon veya kararların alınması gereken herhangi bir bağlam olabilir.
- Durum: Bir durum, bir anın çevresinin bir anlık görüntüsünü temsil eder ve ajanın kararlar alması için kritik bilgiler sağlar.
- Eylem: Ajanın belirli bir durumda alabileceği olası hamlelerin veya kararların kümesi.
- Ödül: Çevreden gelen sayısal bir geri bildirim sinyali, ajanın eyleminin anlık sonucunu gösterir. Amaç, zaman içinde kümülatif ödülleri maksimize etmektir.
- Politika: Ajanın mevcut duruma dayalı olarak eylemlerini belirlemek için takip ettiği strateji veya kurallar kümesi.
Pekiştirmeli öğrenme süreci, ajanın çevre ile bir dizi ayrık zaman adımında etkileşimde bulunduğu bir döngü içerir. Genel akış, şu adımları içerir:
- Gözlem: Ajan, çevrenin mevcut durumunu gözlemler.
- Karar Alma: Ajan, mevcut politikasına dayalı olarak bir eylem seçer.
- Eylem Gerçekleştirme: Seçilen eylem çevrede gerçekleştirilir.
- Ödül Alma: Ajan, eyleminin sonucuna bağlı olarak bir ödül veya ceza alır.
- Öğrenme: Ajan, geri bildirim alınan temelinde politikasını günceller ve gelecekteki karar alma yeteneğini iyileştirmeyi amaçlar.
Pekiştirmeli Öğrenme'nin Uygulamaları:
- Oyun Oynama: Pekiştirmeli öğrenme, Go, Satranç ve video oyunları gibi karmaşık oyunlarda olağanüstü başarılar göstererek insan performansını aşmıştır.
- Robotik: Otonom robotlar, çevrelerine uyum sağlamayı öğrenmek ve gerçek dünya senaryolarında daha çok yönlü hale gelmek için PO kullanır.
- Finans: Pekiştirmeli öğrenme, algoritmik ticaret ve portföy optimizasyonunda kullanılır; ajanlar karlı yatırım kararları almaya öğrenir.
- Sağlık: Pekiştirmeli öğrenme, kişiselleştirilmiş tedavi planlarında, ilaç keşfinde ve sağlık alanındaki kaynak tahsisini optimize etmede yardımcı olur.
- Otonom Araçlar: Pekiştirmeli öğrenme, otomatik araçların karmaşık trafik senaryolarında eğitilmesinde ve optimal kararlar almasında kritik bir rol oynar.
Pekiştirmeli Öğrenme'deki Zorluklar:
- Keşfetme-Exploitasyon Çıkmazı: Yeni eylemleri keşfetme ve bilinenleri kullanma ihtiyacını dengeleme, Pekiştirmeli öğrenme tekniğindeki temel bir zorluktur.
- Kredi Atama Problemi: Bir eylemin ve alınan ödül arasındaki gecikme olduğunda, belirli bir sonuca katkıda bulunan eylemlerin belirlenmesi zor olabilir.
- Karmaşıklık ve Ölçeklenebilirlik: Pekiştirmeli öğrenme modelleri daha karmaşık hale geldikçe, bunları büyük ölçekli ortamlarda eğitmek hesaplama zorlukları doğurur.
Son Gelişmeler:
- Derin Pekiştirmeli Öğrenme : Derin sinir ağlarının pekiştirmeli öğrenme ile bütünleştirilmesi, ajanların karmaşık temsiller öğrenmelerini sağlar ve çeşitli görevlerde insan seviyesinde performans elde etmelerine olanak tanır.
- Proksimal Politika Optimizasyonu : Politika fonksiyonlarını istikrarlı ve etkili bir şekilde optimize eden bir algoritma; geleneksel politika gradyan yöntemlerindeki bazı zorlukları ele alır.
- Çok Ajanlı Pekiştirmeli Öğrenme: Pekiştirmeli öğrenme, birbirleriyle etkileşimde bulunan çoklu ajan senaryolarına genişletme, işbirliği ve rekabeti teşvik eder.
Sonuç:
Pekiştirmeli Öğrenme, zeki ajanları karar almaya eğitmek için güçlü bir paradigmayı temsil eder. Algoritmalar ve hesaplama kaynaklarındaki gelişmeler devam ettikçe, Pekiştirmeli öğrenme tekniğinin uygulamaları endüstrileri devrimleştirmeye ve daha yetenekli, adapte olabilir ve otonom sistemlerin gelişimine katkıda bulunabilir.


.png)






.png)
.png)


 Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)


 SMEMA Nedir?
SMEMA Nedir?.png)
.png)