Yapay zeka, günümüzde birçok endüstri ve sektörde devrim yaratıyor. Bu devrimin temel taşı, makine öğrenimi olarak adlandırılan bir alt kümesidir. Makine öğrenimi, bilgisayar sistemlerinin deneyimlerinden öğrenmelerini sağlayan ve karmaşık görevleri gerçekleştirebilen algoritmaların geliştirilmesini içerir. Bu yazıda, makine öğrenimi konseptini inceleyecek ve günlük hayatta ve endüstriyel uygulamalarda nasıl kullanıldığını anlayacağız.
Makine Öğrenimi Nedir?
Makine öğrenmesi, yapay zeka alanında önemli bir konu olarak karşımıza çıkmaktadır. Makine öğrenmesi algoritmaları, bilgisayar sistemlerinin veri analizi yaparak öğrenme yeteneğine sahip olmalarını sağlar. Bu algoritmalar, genellikle büyük veri kümeleri üzerinde çalışarak desenleri bulma, tahmin yapma, sınıflandırma oluşturma gibi görevleri yerine getirir. Makine öğrenmesi algoritmaları, birçok farklı uygulama alanında kullanılmaktadır ve bu algoritmaların çeşitliliği ve kullanım alanları da oldukça geniştir.
Makine Öğrenimi Uygulamaları:
- Görüntü Tanıma
Görüntü tanıma, güvenlik sistemlerinden tıbbi teşhislere kadar birçok alanda kullanılır. Yüz tanıma, nesne tanıma, güvenlik kameralarında anormal durum teşhisi, tıbbi görüntülerde lezyon tespiti, eski fotoğrafların restore edilmesi, röntgen veya tomografi görüntülerinden kanser tespiti gibi birçok uygulama alanları vardır. - Doğal Dil İşleme
Doğal dil işleme, bilgisayar sistemlerinin insan dilini anlamasını ve işlemesini sağlar. Sesli asistanlar, çeviri uygulamaları ve duygu analizi, sesli konuşmayı metne dönüştürme, bir dilin yapılarını öğrenme ve dil üretebilme yeteneği, metin verilerinde desenleri ve trendleri analiz etme gibi uygulamalarda kullanılır. - Öneri Sistemleri
Online alışveriş sitelerinde, kullanıcılara kişiselleştirilmiş öneriler sunan sistemler, e-ticaret platformlarında ürün önerileri, müzik ve film platformlarında içerik önerileri makine öğrenimini kullanır. - Sağlık Sektöründe Kullanımı
Makine öğrenimi, hastalıkların tanı/teşhis edilmesi, tıbbi görüntülerde lezyon tespitleri, kan hücrelerinin sayımı, tedavi planlaması ve genetik analizlerde kullanılır. Bu sayede daha hızlı ve etkili sağlık hizmetleri sunulabilir. - Finansal Tahminler
Hisse senetleri, döviz kurları, kredi riski değerlendirmesi, portföy optimizasyonu, faiz oranı tahmini, kredi kartı dolandırıcılığı tespiti ve ekonomik göstergelerin gelecekteki değerlerini tahmin etmek için makine öğrenimi kullanılır.
Makine öğrenmesinde kullanılan farklı algoritmalar, çeşitli problemlere çözüm sağlamak, veri setlerinden öğrenmek ve tahminlerde bulunmak amacıyla kullanılır. Aşağıda, farklı makine öğrenimi algoritmalarının genel bir kısaca açıklaması ve her birinin uygulama örnekleri verilmiştir:
Denetimli Öğrenme Algoritmaları:
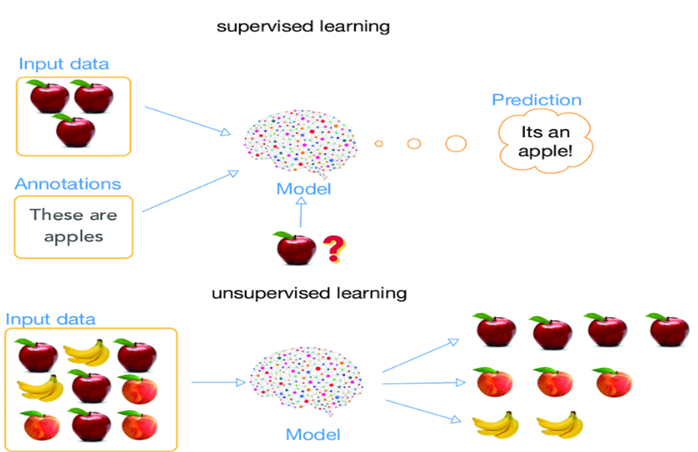
Denetimli öğrenme, eğitim verileri olarak adlandırılan etiketli bir veri seti kullanır, bu veri setinde her giriş verisi ile ilişkilendirilmiş doğru çıktılar bulunur.
Öğrenme süreci, algoritmanın bu etiketli veri seti üzerinde eğitilmesini içerir. Algoritma, bu veri setindeki desenleri tanımak ve genelleme yeteneğini geliştirmek için iteratif olarak güncellenir. Daha sonra, yeni ve görülmemiş veri noktaları üzerinde başarılı tahminler yapabilmesi amaçlanır.
- Lineer Regresyon:
Açıklama: Lineer regresyon, bağımsız değişkenlerle bağımlı değişken arasındaki ilişkiyi modellemek için kullanılır.
Uygulama Örneği: Ev fiyatlarını tahmin etmek için kullanılabilir. - Karar Ağaçları (Decision Trees):
Açıklama: Karar ağaçları, kararlar almak için bir ağaç yapısı kullanır ve sınıflandırma veya regresyon görevlerini gerçekleştirebilir.
Uygulama Örneği: Hastalık teşhisinde kullanılabilir. - Destek Vektör Makineleri (SVM-Support Vector Machine):
Açıklama: SVM, iki sınıf arasındaki ayrım çizgisini (hiper-düzlemi) en iyi şekilde bulmayı amaçlar.
Uygulama Örneği: Görüntü sınıflandırma, metin madenciliği.
Denetimsiz Öğrenme Algoritmaları:
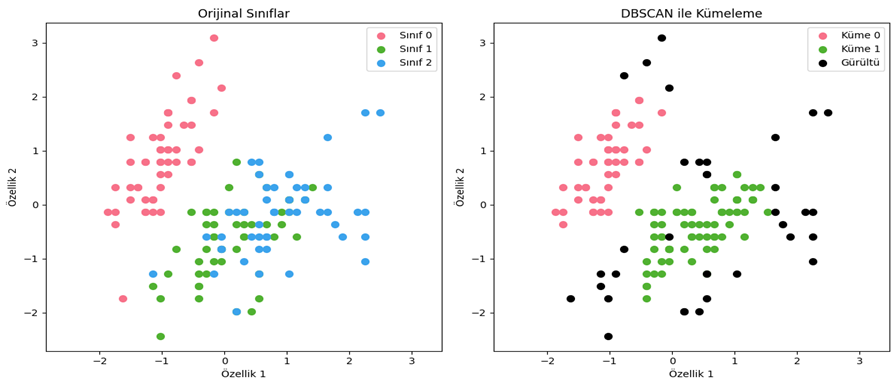
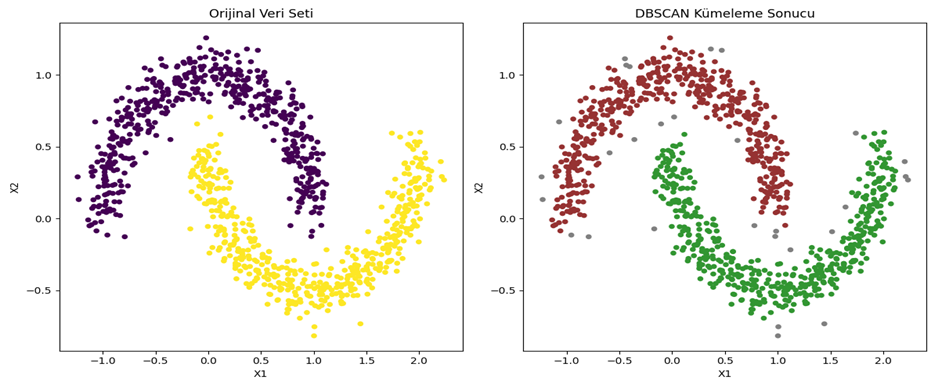
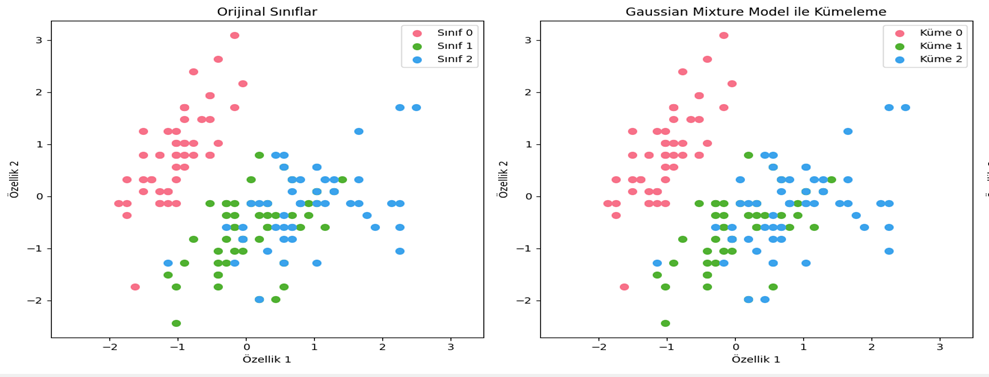
Denetimsiz öğrenme, makine öğrenimi alanındaki önemli bir paradigmadır ve bilgisayar sistemlerinin etiketlenmemiş veri setleri üzerinde öğrenme yeteneğini içerir. Bu öğrenme türü, algoritmaların belirli bir çıktıyı önceden bilmeksizin veri setindeki yapıları ve desenleri keşfetmeye çalıştığı bir öğrenme yaklaşımıdır.
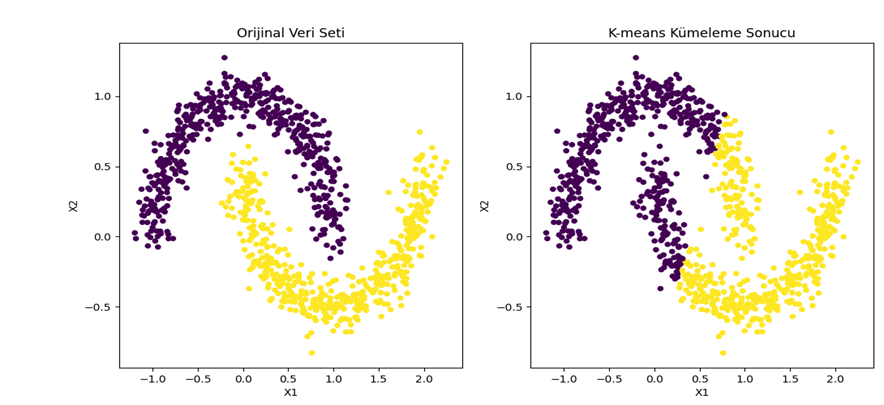
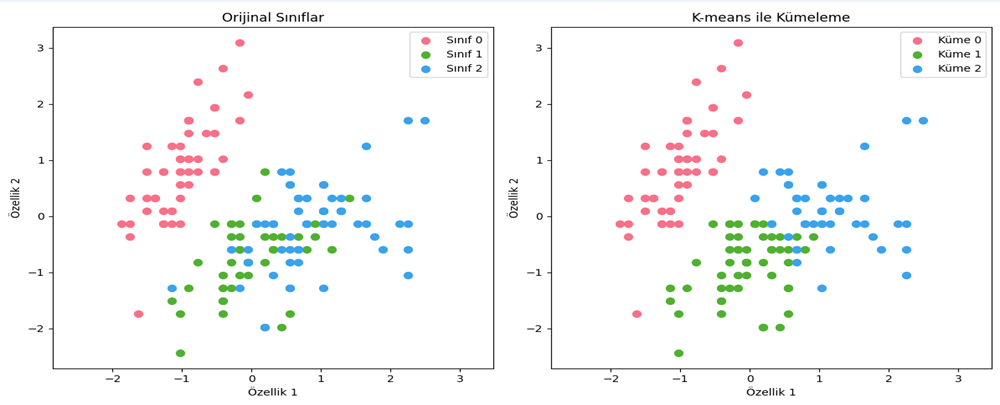
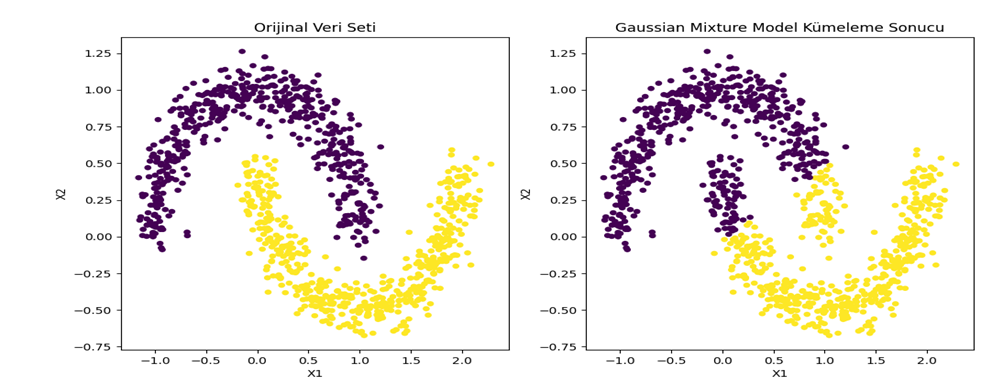
- K-Means Kümeleme:
Açıklama: Veri noktalarını belirli sayıda küme veya grup içine ayırmak için kullanılır.
Uygulama Örneği: Müşteri segmentasyonu. - Hiyerarşik Kümeleme:
Açıklama: Kümeleme, alt kümelemelerin oluşturulduğu bir ağaç yapısını kullanır.
Uygulama Örneği: Biyoinformatikte genetik benzerlik analizi. - Mean-Shift Kümeleme:
Açıklama: Mean-Shift kümeleme, veri noktalarını yoğunluk odaklarına çekmek için bir iteratif algoritma kullanır. Her bir veri noktası, çevresindeki yoğunlukla ağırlıklandırılır ve bu ağırlıklı ortalama, yeni bir konum belirler.
Uygulama Örneği: Kentsel alanlarda nüfus yoğunluğu analizi için kullanılabilir. - Naive Bayes:
Açıklama: Sınıflandırma problemleri için olasılık tabanlı bir yaklaşım kullanır.
Uygulama Örneği: E-posta sınıflandırması. - K-Nearest Neighbor (KNN):
Açıklama: Bir veri noktasını etiketlemek için k-yakın komşularını kullanır.
Uygulama Örneği: Spam filtreleme.
Takviyeli (Pekiştirmeli) Öğrenme:
- Q-Öğrenme(Q Learning):
Pekiştirmeli (Reinforcement) öğrenme, bir ajanın çevresiyle etkileşimde bulunarak belirli bir görevi öğrenmesini sağlayan bir öğrenme paradigmasıdır. Q-öğrenme, özellikle karmaşık karar verme süreçlerinde ve oyun teorisinde kullanılır.
Açıklama: Bir ajanın belirli bir durumda hangi eylemi seçeceğini öğrenir.
Uygulama Örneği: Oyun oynayan yapay zeka. - Politika Gradyanı Yöntemleri (Policy Gradient Method):
Politika Gradyanı Yöntemi, takviyeli öğrenme alanında kullanılan bir algoritma türüdür. Bu yöntem, bir ajanın belirli bir ortamda bir görevi başarıyla gerçekleştirebilmek için uyguladığı karar stratejisinin (politikanın) doğrudan optimize edilmesine odaklanır. Politika, bir durumda belirli bir eylemi seçme olasılığını ifade eder.
Açıklama: Eylem stratejisini optimize etmek için kullanılır.
Uygulama Örneği: Robot kontrolü.
Her algoritmanın avantajları, dezavantajları ve belirli kullanım durumları vardır. Hangi algoritmanın seçileceği, veri setinin özelliklerine, problemin karmaşıklığına ve performans gereksinimlerine bağlıdır.
Yarı-Denetimli Öğrenme:
- Etiketli Veri Kullanımı: Yarı denetimli öğrenme, öncelikle etiketli verilerle başlar. Böylelikle öğrenme algoritmasının belirli bir görevdeki doğru çıktıları öğrenmesine yardımcı olur.
- Etiketsiz Veri Kullanımı: Ardından, etiketlenmiş verilerle birlikte etiketsiz veriler de kullanılır. Etiketsiz veriler, modelin daha genel bir deseni veya veri dağılımını öğrenmesine yardımcı olabilir.
- Transfer Öğrenme ve Öğrenilmiş Temsiller: Yarı denetimli öğrenme, etiketlenmiş veriler üzerinde öğrendiği bilgileri, etiketsiz veriler üzerinde genelleme yeteneği kazanmak için kullanabilir. Öğrenilen bilgiler, transfer öğrenme prensiplerini içerir.
Uygulama Alanları ve Örnekler:
- Metin Madenciliği ve Duygu Analizi:
Senaryo: Bir şirket, müşteri geribildirimlerini incelemek istiyor. - Uygulama: Etiketlenmiş verilerle (olumlu/negatif) başlanır ve ardından etiketsiz verilerle genel duygu eğilimleri belirlenir.
- Görüntü Tanıma:
Senaryo: Belirli bir nesnenin tanımlanması isteniyor. - Uygulama: Etiketli verilerle (belirli nesnenin görüntüleri) başlanır ve ardından etiketsiz verilerle genel nesne tanıma yetenekleri geliştirilir.
Diller:
Makine öğrenmesi uygulamaları çeşitli diller ve kütüphaneler kullanılarak geliştirilebilir. İşte yaygın olarak kullanılan bazı diller, kütüphaneler ve kullanım alanları:
- Python:
Kütüphaneler: TensorFlow, PyTorch, Scikit-learn, Keras, NumPy, Pandas.
Kullanım Alanları: Görüntü işleme, doğal dil işleme, sınıflandırma, regresyon. - R:
Kütüphaneler: Caret, ggplot2, randomForest, e1071.
Kullanım Alanları: İstatistiksel analiz, veri görselleştirme, regresyon analizi. - Java:
Kütüphaneler: Deeplearning4j, Weka, Apache OpenNLP.
Kullanım Alanları: Büyük veri analizi, metin madenciliği, sınıflandırma. - C++:
Kütüphaneler: Dlib, Shark, Mlpack.
Kullanım Alanları: Gömülü sistemler, bilgisayar görüşü, özel optimizasyon gerektiren uygulamalar.
Kütüphaneler:
- TensorFlow:
Dil: Python, C++, Java.
Kullanım Alanları: Derin öğrenme, görüntü işleme, doğal dil işleme. - PyTorch:
Dil: Python.
Kullanım Alanları: Derin öğrenme, bilgisayar görüşü, doğal dil işleme. - Scikit-learn:
Dil: Python.
Kullanım Alanları: Sınıflandırma, regresyon, kümeleme, boyutsal azaltma. - Keras:
Dil: Python.
Kullanım Alanları: Derin öğrenme, sinir ağı modelleri. - Weka:
Dil: Java.
Kullanım Alanları: Veri madenciliği, sınıflandırma, regresyon.
Kullanım Alanları:
- Görüntü İşleme:
Kullanılan Kütüphaneler: OpenCV, scikit-image, Pillow.
Uygulamalar: Yüz tanıma, nesne tespiti, görüntü sınıflandırma. - Doğal Dil İşleme:
Kullanılan Kütüphaneler: NLTK, SpaCy, TextBlob.
Uygulamalar: Metin sınıflandırma, duygu analizi, dil modelleme. - Derin Öğrenme:
Kullanılan Kütüphaneler: TensorFlow, PyTorch, Keras.
Uygulamalar: Resim tanıma, dil çevirisi, ses tanıma. - Sınıflandırma ve Regresyon:
Kullanılan Kütüphaneler: Scikit-learn, XGBoost, LightGBM.
Uygulamalar: Hastalık teşhisi, finansal tahminler, pazar analizi. - Kümeleme:
Kullanılan Kütüphaneler: K-Means, Hierarchical Clustering.
Uygulamalar: Müşteri segmentasyonu, görüntü bölütleme. - Büyük Veri Analizi:
Kullanılan Kütüphaneler: Apache Spark MLlib.
Uygulamalar: Büyük veri madenciliği, paralel makine öğrenmesi.
Her dil ve kütüphane, belirli uygulama alanlarına daha uygun olabilir ve seçim, projenin ihtiyaçlarına, geliştirici deneyimine ve kullanılan platforma bağlı olarak değişebilir.
Sonuç:
Gelecekte, makine öğrenimi daha da önem kazanacak ve daha gelişmiş uygulama alanlarıyla karşılaşacağız. Otomasyonun artması, daha akıllı kararlar alabilen sistemlerin ortaya çıkması ve daha etkili çözümler sunulması, makine öğreniminin potansiyelini daha da artıracaktır.
Sonuç olarak, makine öğrenimi, teknolojinin geldiği noktada önemli bir oyuncu haline gelmiş ve gelecekteki inovasyonların temelini oluşturacaktır. Bu alana olan ilgi ve yatırımların artmasıyla, makine öğrenimi çözümleri daha da güçlenecek ve yaşamımızın birçok alanında etkisini sürdürecektir.


.png)






.png)
.png)


 Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)


 SMEMA Nedir?
SMEMA Nedir?.png)
.png)