




























-
 DEVAMI
DEVAMIYapay zekâ dünyasında yön artık net biçimde değişti: “konuşan” modellerden, gerçekten iş yapan modellere geçiyoruz. Sadece metin üretmekle yetinmeyen; karar alabilen, farklı araçları kullanabilen ve uçtan uca süreçleri yönetebilen sistemler gündemde. Peki, teknoloji dünyasının yeni favorisi olan AI Agent (Yapay Zekâ Ajanı) aslında tam olarak nedir?
AI Agent Nedir?
AI Agent, çevresindeki bilgileri algılayan, verileri anlamlandıran ve belirli bir hedefe ulaşmak için kendi başına kararlar alarak harekete geçen bir yazılım sistemidir. Geleneksel yazılımlardan farklı olarak, her adımı en baştan tek tek kodlamanız gerekmez; siz sadece bir hedef tanımlarsınız (örneğin: “Gelen faturaları ayıkla ve muhasebe sistemine kaydet”). AI Agent ise sahip olduğu araçları kullanarak bu hedefe nasıl ulaşacağını kendisi planlar ve uygular.
AI Agent'ın Türleri Nelerdir?
AI Agent'lar karmaşıklık seviyelerine ve çalışma prensiplerine göre genellikle şu kategorilere ayrılır:
- Basit Refleks Ajanları (Simple Reflex Agents): Sadece anlık duruma göre hareket ederler. "Eğer X olursa Y yap" mantığıyla çalışırlar (Örneğin: Sıcaklık 25 dereceyi geçerse klimayı aç).
- Model Tabanlı Ajanlar (Model-Based Reflex Agents): Dünyanın nasıl işlediğine dair içsel bir modele ve hafızaya sahiptirler. Geçmiş durumları hatırlayarak şimdiki kararlarını şekillendirebilirler.
- Hedef Tabanlı Ajanlar (Goal-Based Agents): Ellerinde net bir hedef vardır ve bu hedefe ulaşmak için farklı senaryoları değerlendirip en doğru yolu seçerler.
- Fayda Tabanlı Ajanlar (Utility-Based Agents): Sadece hedefe ulaşmayı değil, o hedefe "en verimli" (en hızlı, en ucuz veya en güvenli) şekilde ulaşmayı amaçlarlar.
- Öğrenen Ajanlar (Learning Agents): Deneyimlerinden ders çıkararak zamanla performanslarını artırırlar.

Şekil-1: Yapay Zeka Ajan Türleri
AI Agentları ve Büyük Dil Modelleri Arasındaki Fark
Büyük Dil Modelleri (LLM'ler) ile AI Agent'lar sıklıkla karıştırılsa da aralarında temel bir fark vardır: Eylem.
- LLM (Örn: GPT-5, Claude): Muazzam bir bilgi birikimine sahip bir ansiklopedi veya çok zeki bir yazar gibidir. Ona bir soru sorarsınız, o da size cevap verir. Ancak, kendi başına dış dünyada bir değişiklik yapamaz.
- AI Agent: LLM'i "beyin" olarak kullanır ancak buna "eller ve kollar" (araçlar) ekler. Bir Agent, LLM'in ürettiği planı alır ve API'ler aracılığıyla e-posta gönderir, veritabanına kayıt girer veya internette araştırma yapar.
AI Agent Ekosistemi: Platformlar, Otomasyon ve Zorluklar
Yapay zeka ajanlarını sadece tanımlamak yetmez; onları nasıl inşa edeceğimizi, hangi platformlarda çalıştıracağımızı ve başarılarını nasıl ölçeceğimizi anlamak, 2025 yılı itibarıyla işletmeler için kritik bir yetkinlik haline geldi.
1. İş Dünyası İçin Kritik Platformlar
Bernard Marr’ın Forbes’ta (Aralık 2025) yayınlanan analizine göre, iş dünyası liderleri için AI Agent’lar artık sadece bir deneysel teknoloji değil, doğrudan değer yaratan bir stratejik araç olarak konumlanıyor. Artık işletmeler, müşteri hizmetlerinden veri analizine, üretim planlamasından finansal raporlamaya kadar birçok alanda “dijital işçi” istihdam etmeyi amaçlıyor. Bu noktada doğru platformu seçmek kritik hale geliyor.
Öne çıkan platformlar şunlar:
- Microsoft Copilot Studio: Kurumsal düzeyde derin entegrasyon imkânı, Office 365 ve Teams ile doğal uyum.
- Salesforce Agentforce: CRM süreçlerini akıllı otomasyonlarla optimize eder, müşteri etkileşimlerini geliştirmeye odaklanır.
- Google Vertex AI: Büyük veri ve yapay zekâ altyapısıyla ölçeklenebilir ve esnek AI agent geliştirme olanağı sunar.
- UiPath Studio: Özellikle süreç otomasyonu ve RPA (Robotik Süreç Otomasyonu) ile manuel iş yükünü azaltır.
- OpenAI AgentKit: Geliştirici odaklı, özelleştirilebilir agentlar tasarlamaya olanak tanır ve farklı platformlarla kolay entegrasyon sunar.
Bu platformlar, işletmelerin sadece süreçleri otomatikleştirmekle kalmayıp, AI agent’ları şirketin stratejik karar süreçlerine entegre etmesine imkân tanıyor. Örneğin, müşteri hizmetlerinde otomatik talep sınıflandırması ve yönlendirmesi yapılırken, aynı agent pazarlama kampanyalarının etkisini de analiz edebiliyor. Böylece AI agent, sadece iş yükünü azaltan bir araç değil, veriye dayalı karar sürecini destekleyen bir iş ortağı hâline geliyor.
2. İnşa Süreci: n8n, Zapier, Langflow, Flowise ve Make Karşılaştırması
Bir AI Agent kurgularken, “beyni” (LLM) ve “vücudu” (uygulamalar, veri kaynakları, araçlar) birleştiren entegrasyon katmanı kritik öneme sahip. Bu katman, agent’ın hem görevleri doğru biçimde yerine getirmesini sağlar hem de iş akışının karmaşıklığına uygun esneklik sunar. Bu noktada n8n, Zapier, Langflow, Flowise ve Make karşılaştırması öne çıkıyor.
- Maliyet ve Ölçek: Zapier ve Make görev veya operasyon başına ücretlendirir; karmaşık AI agent’lar yüzlerce döngü ve karar adımı çalıştırdığında maliyet hızla artar. n8n ise workflow execution bazlı ve self-hosting imkânıyla bu maliyeti kontrol altında tutar, karmaşık iş akışlarını ekonomik ve ölçeklenebilir çalıştırır.
Langflow ve Flowise gibi agent tasarımına odaklanan açık kaynaklı araçlar da self-host edilebilir ve lisans maliyeti yaratmaz. Ancak bu platformlarda toplam maliyet, otomasyon adımlarından ziyade LLM çağrıları ve agent reasoning sıklığına bağlıdır
- Gizlilik ve Esneklik: n8n’in açık kaynaklı ve yerel çalışabilen yapısı, veri gizliliği gerektiren senaryolarda büyük avantaj sağlar. Örneğin, müşteri e-postalarını analiz eden ve CRM verilerini kullanan bir agent, verileri şirket dışına çıkarmadan güvenli biçimde çalışabilir.
Langflow ve Flowise ise agent prompt’larının, memory yapılarının ve vektör verilerinin kurum içinde tutulmasına imkân tanır. Ancak kurumsal sistemlerle derin entegrasyon ve uçtan uca süreç yönetimi, pratikte n8n gibi bir orkestrasyon katmanıyla birlikte kullanıldığında anlam kazanır.
- İş Akışının Karmaşıklığına Uyum: Zapier lineer ve basit, Make dallanabilen akışlar sunar; n8n ise karmaşık döngüler, koşullar ve alt workflow’lar ile agent’ların farklı senaryolara esnek şekilde uyum sağlamasına olanak tanır.
Langflow ve Flowise, iş akışının tamamını yönetmekten ziyade agent’ın iç karar alma mantığını görsel olarak kurgulamak için öne çıkar. n8n ise bu agent’ları tetikleyen, gerekli verileri sağlayan, çıktıları kurumsal sistemlere aktaran ve tüm süreci operasyonel düzeyde yöneten orkestrasyon katmanı olarak konumlanmaktadır.
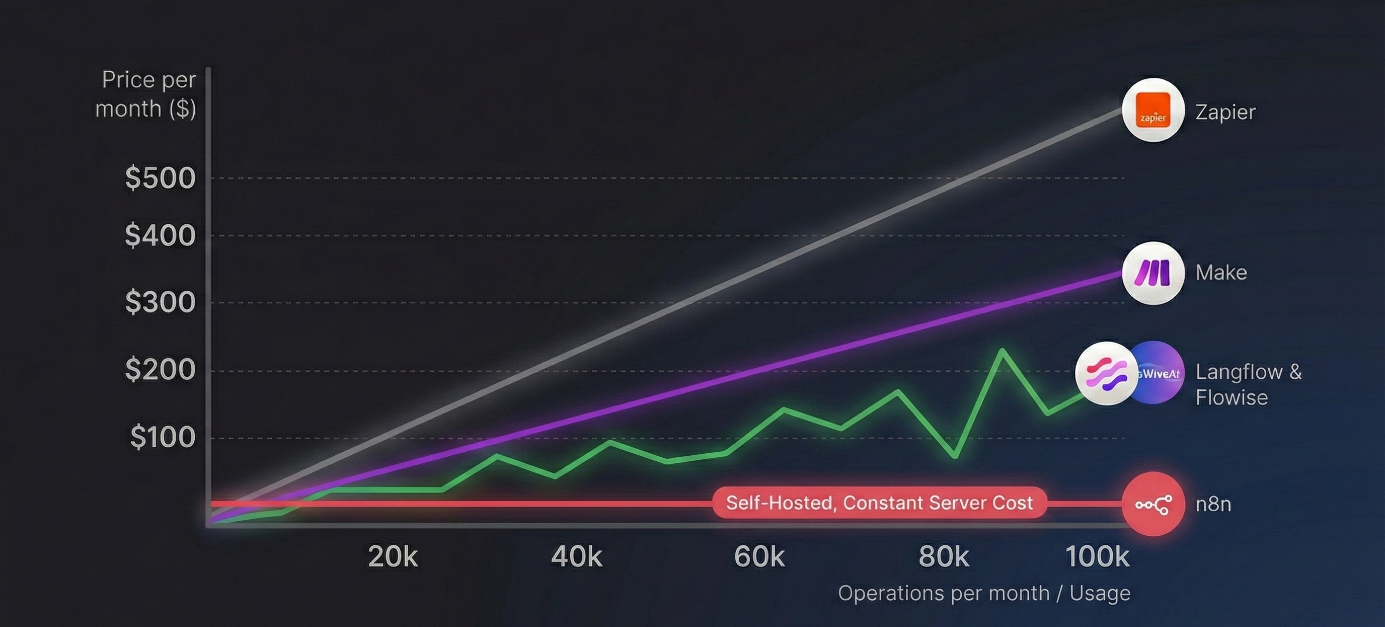
Şekil-2: Popüler AI Agent Otomasyon Platformları Maliyet Karşılaştırması
Görsel, işlem hacmi arttığında maliyetlerin nasıl değiştiğini özetliyor:
- Zapier : Her işlem adımını ücretlendirdiği için maliyet doğrusal olarak artar ve ayda 500 doları aşabilir.
- Make : Zapier'den ucuz olsa da işlem sayısı arttıkça faturanız kabarmaya devam eder.
- n8n : Grafikteki düz çizginin sebebi, n8n'in "Self-Hosted" modelidir. İşlem sayısı ne kadar artarsa artsın yazılım maliyeti 0$ kalır; sadece yaklaşık 3-6$'lık sunucu kirası ödersiniz.
- Langflow & Flowise: Platform maliyeti sabit (0 USD) olsa da grafik LLM kullanımına bağlı dalgalı bir yapı gösterir. Agent ne kadar sık düşünür, çağrı yapar ve memory kullanırsa toplam maliyet o kadar yükselir; bu nedenle üretim ortamlarında dikkatli mimari tasarım gerektirir.
3.Bir AI Agent'ın Başarısını Nasıl Ölçeriz?
Platformu seçtik (örneğin n8n) ve ajanı kurduk. Peki, gerçekten iyi çalışıp çalışmadığını nasıl anlayacağız? Geleneksel yapay zekâ modellerinde başarıyı sadece cevap doğruluğuna bakarak ölçebilirdik. Ancak modern AI agent’lar gerçek dünyada eylem yapar: veritabanına kaydeder, randevu oluşturur veya para transferi başlatır. Bu durumda başarıyı yalnızca metin çıktısıyla değerlendirmek mümkün değildir.
.png)
Şekil-3: Farklı Büyük Dil Modellerinin Performans Karşılaştırması
AI agent performansını ölçmek için üç temel kriter vardır:
- Durum Kontrolü : Ajan “Randevuyu iptal ettim” dediğinde, gerçekten takvimde o randevunun silinip silinmediğini kontrol etmelisiniz. Başarı, metinde değil, veritabanındaki gerçek durumdadır.
- Maliyet ve Gecikme : Ajan görevi tamamladı, peki bunu yaparken ne kadar kaynak kullandı ve ne kadar sürede tamamladı? İş dünyasında sadece “doğru cevap” değil, hızlı ve ekonomik sonuç da önemlidir.
- Tekrarlanabilirlik : Ajan aynı komutu iki kez aldığında ne yapıyor? Aynı faturayı iki kere mi ödüyor, yoksa “Bu işlem zaten tamamlandı” diyebiliyor mu? Tekrarlanabilirlik, sistemin güvenli ve hatasız çalışması için hayati önemdedir.
AI agent’lar klasik yapay zekâ modellerinden farklı olarak durum yönetimi ve eylem odaklı performans sergiler. Başarısını ölçmek için yalnızca cevap doğruluğuna değil; veri bütünlüğüne, maliyet-hız dengesine ve işlem güvenliğine bakmak gerekir. Bir agent’ın gerçek değeri, zekâsıyla değil, görevleri güvenli, verimli ve hatasız tamamlayabilme kapasitesiyle ortaya çıkmaktadır.
4. AI Agent Hafızası: Bağlamı Nasıl Koruruz?
Başarı kriterlerini belirledik, ancak sürdürülebilir bir performans için kritik bir eksik parça daha var: Hafıza. Standart dil modelleri doğası gereği “unutkandır”; her yeni sohbette sizi ilk kez görüyormuş gibi davranırlar. Ancak bir AI Agent’ın gerçek bir asistan gibi çalışabilmesi için önceki konuşmaları, kullanıcı tercihlerini ve yarım kalan işleri hatırlaması gerekir.
Güçlü bir AI agent hafızası şu üç temel katmandan oluşur:
- Kısa Vadeli Hafıza (Bağlam Penceresi): Ajanın o anki sohbet akışını ve anlık bağlamı takip edebilme yeteneğidir. Örneğin, bir önceki mesajda bir rapordan bahsedip, hemen ardından “Bunu mail at” dediğinizde; ajanın “bunu” kelimesinin o raporu temsil ettiğini anlaması kısa vadeli hafıza sayesinde mümkündür.
- Uzun Vadeli Hafıza (Vektör Veritabanları): Sohbet penceresi kapansa bile ajanın bilgileri kalıcı olarak saklamasıdır. Ajanın, haftalar önce belirttiğiniz “Raporları her zaman PDF formatında istiyorum” tercihini veya geçmiş proje detaylarını hatırlaması bu katmanda gerçekleşir. Bu bilgiler genellikle vektör veritabanlarında saklanır ve ihtiyaç duyulduğunda geri çağrılır.
- Bilgi Geri Çağırma (Retrieval / RAG): Her şeyi hatırlamak verimsizdir; önemli olan doğru bilgiyi doğru zamanda hatırlamaktır. Ajanın, hafızasındaki devasa veri yığını arasından sadece o anki sorununuzla ilgili olan en alakalı parçayı bulup getirmesi, işlem maliyetini düşürür ve halüsinasyon riskini engeller.
Hafıza, bir AI modelini basit bir soru-cevap botundan, sizi tanıyan ve iş akışınıza uyum sağlayan proaktif bir iş ortağına dönüştürür. Etkili bir hafıza mimarisi olmadan, en zeki model bile her gün işi sıfırdan öğrenmek zorunda kalan bir stajyerden farksızdır.
Biz AI Agent’lara Nasıl Yaklaşıyoruz ?
AI agent projelerinde yaklaşımımız, tek bir modeli veya aracı devreye almakla sınırlı kalmıyor; belirli bir iş problemini uçtan uca çözen, üretim ortamında çalışan sistemler geliştiriyoruz. Her projeye, “Agent bu süreçte hangi kararı verecek, hangi sistemi ne zaman güncelleyecek ve başarısını hangi metriklerle ölçeceğiz?” sorularının cevaplarını netleştiriyoruz.
Uygulamada izlediğimiz mimari yaklaşım şu şekilde ilerliyor:
- LLM’leri, agent’ın e-posta, doküman, form ve API gibi farklı girdileri yorumladığı; alternatif aksiyonları değerlendirdiği ve eylem kararını ürettiği karar katmanı olarak konumlandırıyoruz. Örneğin, sisteme gelen bir faturanın otomatik olarak ödenip ödenmeyeceğine, itiraz sürecine alınıp alınmayacağına ya da manuel inceleme gerektirip gerektirmediğine bu katmanda karar verilir.
- İş akışı otomasyonlarını, alınan kararların gerçek iş süreçlerine yansıdığı operasyonel orkestrasyon katmanı olarak kullanıyoruz. Muhasebe kayıtlarının açılması, ERP statülerinin güncellenmesi, ilgili kişilere bildirim gönderilmesi ve hata durumlarında sürecin geri alınması bu katmanda yönetiliyor.
- Kurumsal veri kaynaklarını (CRM, ERP ve veritabanları) agent için tek gerçeklik noktası olarak tanımlıyoruz. Agent’ın yalnızca doğrulanmış verilerle çalışmasını sağlıyor, yapılan her eylemin ilgili sistemlerde iz bırakacak şekilde kaydedilmesini garanti ediyoruz.
Bu yaklaşım sayesinde:
- Aynı agent ile yüzlerce benzer talebi manuel müdahale olmadan ve tutarlı biçimde işliyoruz.
- Tüm aksiyonları, hangi veriyle ve hangi karar sonucunda alındığını gösterecek şekilde geriye dönük olarak izleyebiliyoruz.
- Agent performansını, üretilen metinler üzerinden değil; tamamlanan işlem sayısı, hata oranı, işlem süresi ve maliyet gibi somut metriklerle ölçüyoruz.
Bizim için bir AI agent’ın gerçek değeri, verdiği cevapların ne kadar akıllı olduğunda değil; iş süreçlerini güvenli, tekrar edilebilir ve ölçeklenebilir şekilde çalıştırabilmesinde ortaya çıkıyor. Bu nedenle geliştirdiğimiz agent’ları deneysel prototipler olarak değil, üretim ortamında aktif çalışan dijital iş bileşenleri olarak konumlandırıyoruz.
-
 DEVAMI
DEVAMIKümeleme yöntemleri, etiketlenmemiş verileri belirli metriklere dayanarak gruplandırmak ve ayırmak için kullanılan bir makine öğrenmesi yaklaşımıdır. İlgili yöntemler, çalışma prensiplerine veya kullandıkları benzerlik ölçüm tekniklerine göre birçok farklı türe sahiptir. Peki, etiketli ve etiketsiz veri kavramları neyi ifade eder?
• Etiketli Veriler: Bir yapay zeka modelinin elma ve muzu ayırt etmesini istediğimizi düşünelim. Elma ve muz resimlerini eğitim verisi olarak modelimize verirken, her bir resmin hangi meyveye ait olduğunu açıkça belirtiriz. Yani, resimler "elma" veya "muz" olarak etiketlenmiştir. Ayrıca, elma ve muzun özelliklerini (örneğin rengi, boyutu, şekli vb.) sağlayarak, özelliklerin hangi nesneye ait olduğunu gösteririz. Böylelikle model, etiketli veriler üzerinden öğrenerek yeni gelen verileri doğru bir şekilde sınıflandırmayı öğrenir.
• Etiketsiz Veriler: Şimdi ise yapay zekaya sadece elma ve muzun özelliklerini verdiğimiz, ancak bu özelliklerin hangi meyveye ait olduğunu belirtmediğimiz bir senaryo düşünelim. Yani, elma ve muza ait özellikler mevcut, ancak hangi özelliğin elmaya, hangisinin muza ait olduğunu söylemiyoruz. Bu durumda model, verilerdeki benzerlik ve farklılıkları analiz eder. Benzer özelliklere sahip olanları aynı grupta toplayabilir.Bu süreçte kümeleme yöntemleri kullanılır ve model, verileri doğal olarak oluşan gruplara ayırır.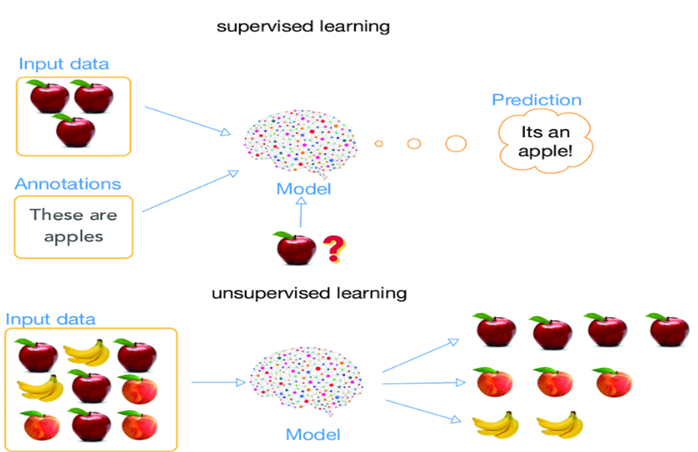
Şekil 1 - Denetimli ve denetimsiz öğrenme
Peki, yapay zeka verideki örneklerin hangi sınıfa ait olduğunu bilmeden elma ve muzu nasıl ayırt edebilir? Bu sorunun cevabına geçmeden önce, neden etiketsiz verilerle çalışmanın önemli olduğunu açıklığa kavuşturalım.
Etiketli verilerle çalışmak genellikle daha avantajlıdır çünkü modelin performansını rahatça test edebilir ve amaca uygun olarak veri veya model üzerinde manipülasyonlar yapabiliriz. Etiketli verilerde, her bir örneğin hangi sınıfa ait olduğunu bildiğimiz için modelin doğruluğunu doğrudan değerlendirebiliriz. Ancak, gerçek hayattaki problemlerimizde elimizdeki verilerin hangi sınıfa ait olduğunu her zaman bilemeyebiliriz veya bu verileri etiketlemek çok maliyetli ve zaman alıcı olabilir.
• Sosyal Medya: Kullanıcıların paylaşımları, yorumları ve etkileşimleri genellikle etiketlenmeden toplanır. Sosyal medyadan toplanan büyük veri setlerini etiketlemek çok maliyetlidir, çünkü her bir yorumu bir insanın tek tek okuması ve değerlendirmesi gerekir.
Bu nedenle, etiketsiz verilerle çalışmak zorunda kalabiliriz. Etiketsiz verilerle çalışırken, model verideki örneklerin doğal gruplarını veya kalıplarını keşfetmeye odaklanır. Kümeleme yöntemleri kullanılarak, benzer özelliklere sahip veriler aynı gruplarda toplanır. Bu sayede, yapay zeka elma ve muz gibi farklı sınıfları, sınıf etiketleri olmadan da ayırt edebilir.
Popüler Olan Kümeleme Yöntemlerine Örnekler İle Bir Bakış Atalım:
K-means Kümeleme Algoritması
• Neden Kullanılır?
- Veri Gruplama: Veri setindeki benzer öğeleri gruplamak için kullanılır, böylece veri analizi ve yorumlama kolaylaşır.
- Özellik Seçimi: Veri kümesindeki önemli özelliklerin belirlenmesine yardımcı olur.
- Görüntü İşleme: Görüntüleri benzer özelliklere göre gruplamak için kullanılır, örneğin renklerin gruplandırılması (Bkz. Şekil 2).
Şekil 2 - K-means ile segmente edilmiş görüntü
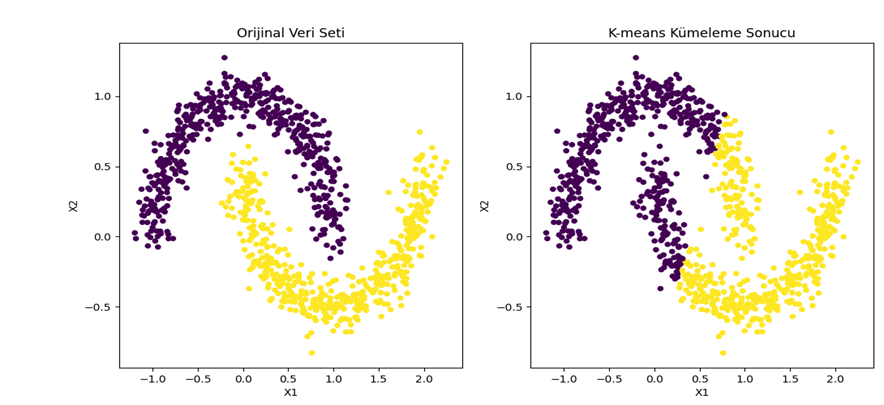
Şekil 3 - Sklearn make_moons veri seti kullanılarak k-means ile kümeleme sonucu
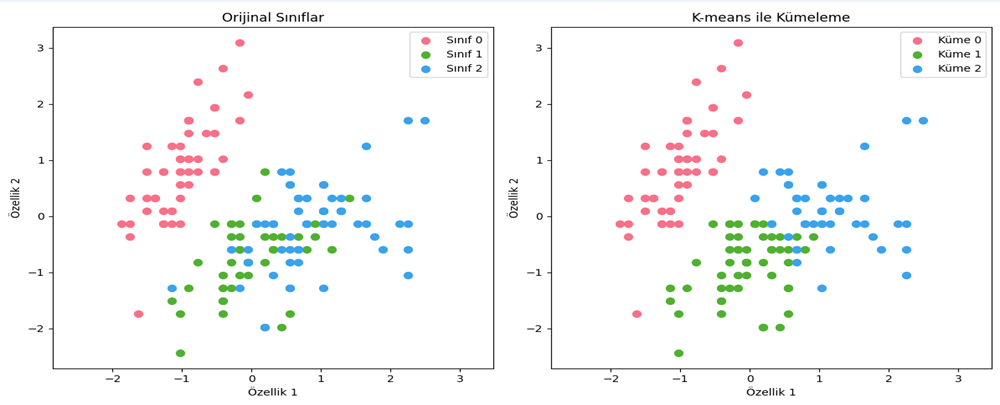
Şekil 4 - Iris veri seti kullanılarak K-means kümeleme sonucuŞekil 3’e ve Şekil 4’e bakıldığında, K-means yönteminin kümeleri dairesel olarak hesapladığı için istenilen performansı veremediği görülmektedir.
DBSCAN Kümele Algoritması
• Neden Kullanılır?
- Yoğunluk Tabanlı Gruplama: Verilerin yoğun olduğu bölgeleri tanımlamak için kullanılır. Yoğun bölgeleri göz önünde bulundurarak veriyi gruplandırır.
- Aykırı Değerlerin Tespiti: Aykırı değerleri (gürültü) belirlemek için etkilidir; yoğun olmayan bölgelerdeki noktalar aykırı olarak kabul edilir (Bkz. Şekil 5).
- Belirgin Kümeler: Küme şekillerinin herhangi bir geometrik yapıya bağlı kalmadan belirlenmesine olanak tanır; bu da karmaşık ve düzensiz formlardaki kümeleri tespit etme yeteneği sağlar (Bkz. Şekil 6).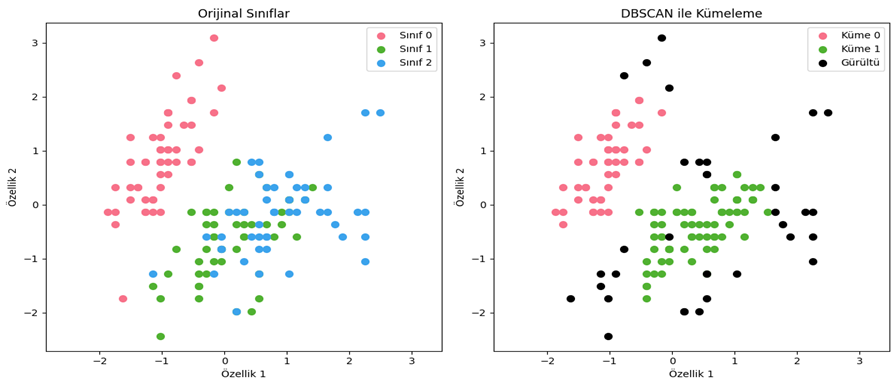
Şekil 5 - Iris veri seti DBSCAN ile kümeleme sonucu
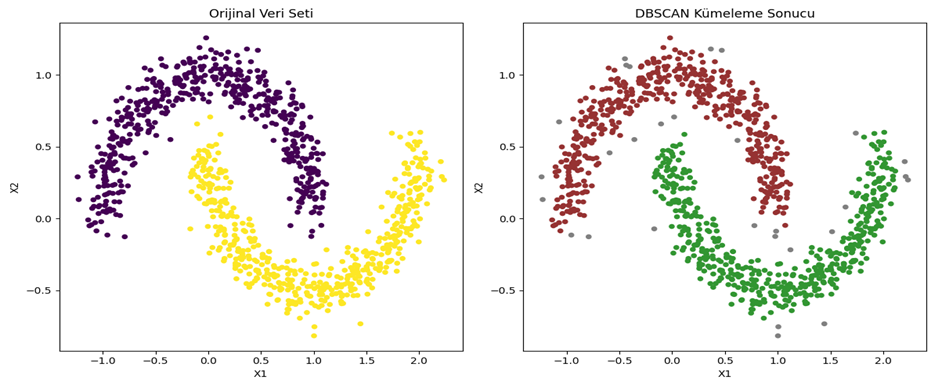
Şekil 6 - Sklearn make_moons veri seti DBSCAN kümeleme sonucuGaussian Mixture Model
• Neden Kullanılır?
- Karmaşık Dağılımlar: GMM, diğer kümeleme yöntemlerinin aksine temelde her küme için Gauss olasılık dağılımını kullandığı için karmaşık veri yapılarında tercih edilebilir (Bkz. Şekil 7).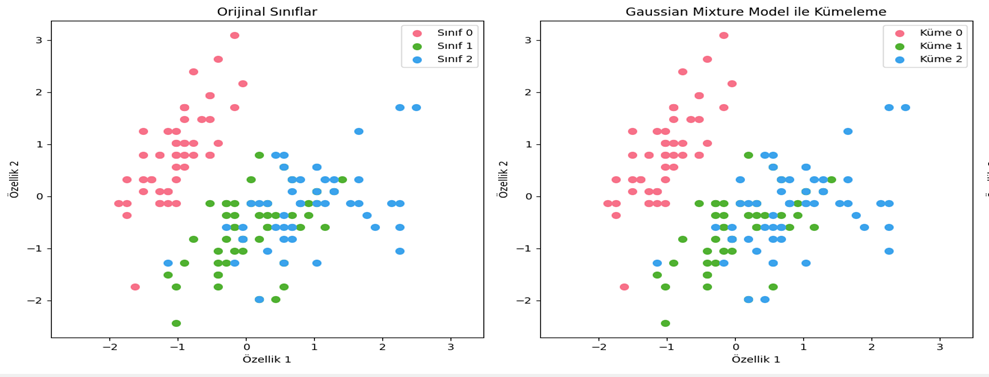
Şekil 7 - Iris veri seti GMM ile kümeleme sonucu
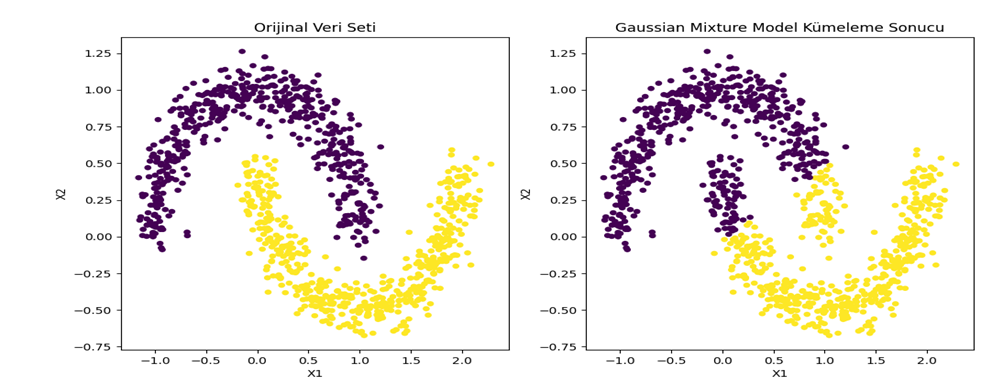
Şekil 8 - Sklearn make_moons veri seti GMM ile kümele sonucuKümeleme Sonuçlarının Değerlendirilmesi ve İyileştirilmesi
Kümeleme algoritmalarının performansını değerlendirmek, doğru sonuçlar elde etmek için kritik bir adımdır. Ancak kümeleme, denetimsiz bir öğrenme yöntemi olduğu için etiketlenmiş veri bulunmadığında sonuçları doğrudan ölçmek zordur. Bununla birlikte, çeşitli metrikler kullanılarak kümelerin kalitesi değerlendirilebilir:
• Silhouette Skoru: Kümedeki her bir örneğin, kendi kümesine olan uzaklığı ile diğer kümelere olan uzaklığı karşılaştırılarak hesaplanır. Skorun yüksek olması, kümelerin iyi ayrıldığını ve içlerinde sıkı bir şekilde gruplandığını gösterir.
• Davies-Bouldin Endeksi: Küme merkezleri arasındaki mesafeleri dikkate alarak kümelerin ne kadar benzer olduğunu ölçen bir metriktir. Düşük bir Davies-Bouldin skoru, iyi ayrılmış kümeler olduğunu işaret eder.
• Rand İndeksi: Verilerdeki benzerlik ve farklılıkları ölçerek kümelerin kalitesini değerlendiren bir metriktir.Bu tür metriklerle kümeleme sonuçları değerlendirilirken, algoritmaların performansı da optimizasyon ile iyileştirilebilir. Örneğin, hiperparametre ayarı veya boyut azaltma teknikleri kullanılarak kümeleme algoritmalarının çıktıları iyileştirilebilir. Bu süreçte, algoritmaya verilen parametreler ve veri özellikleri üzerinde yapılan düzenlemeler, daha doğru ve anlamlı gruplandırmalar elde edilmesine yardımcı olabilir.
Kümeleme ile Aykırı Değerlerin Tespiti
Kümeleme algoritmaları, sadece benzer verileri bir araya getirmekle kalmaz, aynı zamanda aykırı değerleri (outliers) tespit etmek için de kullanılabilir. DBSCAN gibi yoğunluk tabanlı algoritmalar, özellikle bu konuda etkilidir. Yoğun veri noktalarının oluşturduğu kümeler dışında kalan noktalar, aykırı değerler olarak sınıflandırılabilir. Bu aykırı değerler genellikle veri setinde doğal olmayan, yanlış ölçülmüş ya da ekstrem olayları temsil eden verilerdir. Aykırı değerlerin tespiti, birçok alanda önemli bir rol oynar:
• Finans: Dolandırıcılık tespitinde, normal işlem kümelerinden sapmalar gösteren aykırı işlemler tespit edilebilir.
• Sağlık: Hastaların normal sağlık göstergeleri arasından, anormal ve riskli durumlar aykırı değer olarak tespit edilebilir.
• Endüstriyel Sensör Verileri: Üretim hatlarında sensörler tarafından kaydedilen verilerde, cihazlardaki arızaları ya da hatalı ölçümleri bulmak için aykırı değerler incelenir.Kümeleme algoritmaları, farklı sektörlerde ve uygulama alanlarında yaygın olarak kullanılmaktadır. Örneğin, pazarlama alanında şirketler, müşterilerini davranışlarına ve demografik özelliklerine göre segmente etmek için kümeleme algoritmalarına başvururlar. Bu şekilde, hedef kitleyi daha iyi anlayarak pazarlama stratejileri geliştirir ve müşteri memnuniyetini artırırlar. Biyoinformatik alanında ise kümeleme algoritmaları, genetik veri analizlerinde büyük bir rol oynamaktadır. Genom verilerinin kümelenmesi, genler ve proteinler arasındaki ilişkilerin keşfedilmesine olanak tanır ve biyolojik süreçlerin daha iyi anlaşılmasını sağlar.
Görüntü işleme alanında da kümeleme yöntemleri sıkça kullanılır. Özellikle K-means algoritması, görüntülerin segmente edilmesi ve renk kümelerinin ayrıştırılması gibi işlemlerde yaygın bir şekilde tercih edilir. Sosyal medya analizi ise bir diğer önemli uygulama alanıdır. Sosyal medyadan elde edilen büyük veri yığınları, kullanıcıların davranışlarını incelemek, trendleri belirlemek ve kişiselleştirilmiş içerik önerileri oluşturmak için kümeleme algoritmaları ile analiz edilir. Tüm bu örnekler, kümeleme algoritmalarının veri analizinde önemli bir rol oynadığını ve geniş bir yelpazede uygulama alanına sahip olduğunu göstermektedir.
Sonuç
Yapay zekayı güncel hayatta kullanmak istediğimizde karşımıza bazı problemler çıkmaktadır:
• Verilerin etiketsiz olması: Verileri etiketlemeye çalışırken genellikle bir uzmanın yardımına ihtiyaç duyulur. Ancak, alanında uzman bir kişi bile verileri %100 doğru şekilde etiketleyemeyebilir.
• Veri miktarının çok büyük ve karmaşık olması: Büyük boyutlu ve karmaşık verilerle çalışmak, işlemleri zorlaştırır ve daha fazla zaman ve kaynak gerektirir.Bu sebeplerden dolayı, denetimsiz öğrenme yöntemleri güncel hayat problemlerinin çözümünde önemli bir rol oynamaktadır. Bu yazıda, denetimsiz öğrenme yöntemlerinden biri olan kümeleme yöntemleri kısaca ele alınmıştır. K-means, DBSCAN ve GMM (Gaussian Mixture Model) gibi yöntemlerin yanı sıra birçok farklı kümeleme tekniği bulunmaktadır. Karşılaşılan probleme göre, bu yöntemlerin avantaj ve dezavantajları değerlendirilerek en uygun olanı seçilmelidir. Basit ama etkili olan kümeleme yöntemleri, günümüzde bile temel problemleri çözme konusunda geliştiricilere yardımcı olmaktadır.
Referanslar
https://www.researchgate.net/figure/Supervised-learning-and-unsupervised-learning-Supervised-learning-uses-annotation_fig1_329533120
https://www.freecodecamp.org/news/8-clustering-algorithms-in-machine-learning-that-all-data-scientists-should-know/
https://www.geeksforgeeks.org/clustering-based-approaches-for-outlier-detection-in-data-mining/ -
 DEVAMI
DEVAMILisede aldığınız Biyoloji derslerini hatırlayın. Hayatın temelinde yatan karbon atomları belli başlı bazı diğer elementlerle bir araya gelerek organik bileşikleri oluşturuyorlar. Hatta bu organik bileşikler arasında hasta olduğumuzda doktorumuz tarafından bize yazılan o ilaçlar da var. Peki bu moleküller arasında bir örüntü bulabilir miyiz? Veya ileride ortaya çıkacak yeni hastalıkların tedavisi olabilecek ilaçları yapay zeka tasarlayabilir mi?
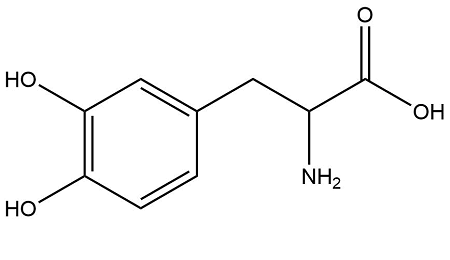
Şekil 1 : Metildopamin Bileşiği(1) (Parkinson Hastalığının Tedavisinde Kullanılır)
Makalemizde bu sorulara cevap vereceğiz. Ancak öncelikle son zamanlarda yapay zeka sektöründe popülerliğini oldukça artırmış yeni bir algoritmadan bahsedeceğiz. Grafik Sinir Ağları, yani GNN’ler.
Grafik Sinir Ağları (GNN’ler) Nedir?
2000'lerin başında veri bilimciler geleneksel yöntemlerle karmaşık ilişkileri modellemekte zorlanıyorlardı. Sosyal ağlar, moleküller ve hatta metinler... Her biri noktalar ve onları birbirine bağlayan çizgilerden oluşan bir ağ gibiydi. Ancak bu ağlardaki gizli ilişkileri ve örüntüleri ortaya çıkarmak kolay değildi. İşte tam bu noktada GNN'ler sahneye çıktı.
GNN'ler temelde ilişkileri anlamak ve analiz etmek için tasarlanmış özel bir derin öğrenme algoritmalarıdır. Veri dünyasındaki pek çok şey aslında birbirleriyle bağlantılı düğümler (node) ve bu düğümler arasındaki kenarlar (edge) ile temsil edilebilir. İşte GNN'ler bu tür "grafik" adı verilen yapılar üzerinde çalışarak, düğümler ve kenarlar arasındaki karmaşık ilişkileri öğrenir ve anlamlı bilgiler çıkarır.
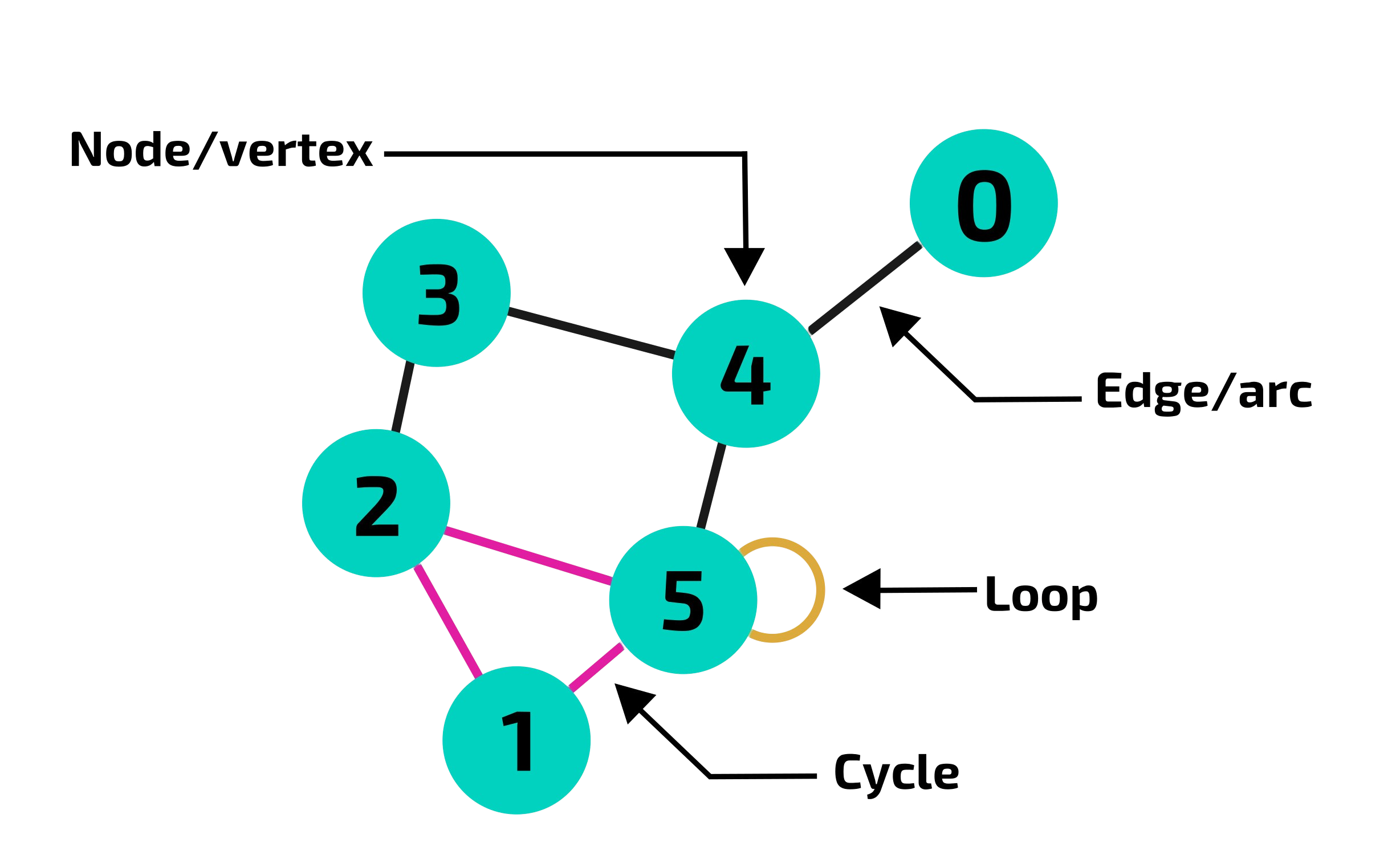
Şekil 2 : Bir Graf (Graph) Örneği(2)İşte bu algoritmalar tıpkı bir dedektif gibi, verinin içindeki bağlantıları takip ederler. Her nokta bir bilgi parçası, her çizgi ise bir ilişkiyi temsil etmektedir. GNN'ler, bu bağlantıların izini sürerek verinin derinliklerindeki sırları açığa çıkarmaya çalışırlar.
GNN’lerin ilk zamanları diğer derin öğrenme algoritmaları gibi oldukça zorlu geçti. GNN'ler henüz emekleme dönemindeydi ve karmaşık problemlerle başa çıkmakta zorlanıyordu. Ancak bilim insanları pes etmedi ve yeni fikirler, yeni algoritmalar geliştirdiler. GNN'ler de zamanla güçlendi ve kendi problemlerini çözmekte oldukça başarılı olmaya başladı. 2010'lar GNN'ler için bir dönüm noktasıydı. Sosyal medyanın patlamasıyla birlikte, devasa boyutlarda sosyal ağlar ortaya çıktı. GNN'ler bu ağlardaki arkadaşlıkları, toplulukları ve hatta sahte hesapları tespit etmekte bir devrim oldu.
İlaç keşfi de GNN'lerin parladığı bir diğer alan oldu. Moleküllerin karmaşık yapısını anlamak, yeni ilaçlar geliştirmek için oldukça kritik bir öneme sahipti. GNN'ler, moleküller arasındaki etkileşimleri modelleyerek bilim insanlarına yeni ilaç adayları bulma konusunda yardımcı oldu. Bugünlerde ise GNN'ler veri biliminin vazgeçilmez araçlarından biri haline geldi. Öneri sistemlerinden trafik tahminine, doğal dil işlemeden metin analizine kadar pek çok alanda kullanılıyorlar.
Peki GNN’lere Neden İhtiyacımız Var?
Günümüzde oldukça popülerliğini koruyan Transformatör (Transformer) algoritmaları ya da diğer birçok algoritma varken neden GNN’leri kullanıyoruz? Tabi bu sorunun birçok cevabı var. Ancak bir tanesi diğer cevaplara göre çok daha önemli, veri yapıları.
Geleneksel yapay zeka modelleri [örneğin evrişimli sinir ağları (CNN'ler)], verileri genellikle düzenli yapılar (listeler, tablolar, görüntüler) halinde işlerler. Ancak gerçek dünyadaki pek çok veri, ağlar (grafikler) şeklinde organize edilir. Örneğin sosyal medyalardaki kişi ağınız, otomobilinizle seyahat ederken kullandığınız otoyol ağınız, alışveriş sitelerinde kullanılan öneri sistemleri, kullandığınız dilin kelimeler ile bağlaçlar arasındaki ilişkileri ve daha önceden anlattığımız moleküller arasındaki ağların ilişkileri; bu tür verileri dijital ortamlarımızda depolamak istediğimizde başvurduğumuz en optimal veri yapıları graflar olacaktır. GNN'ler ise bu tür graf yapılarındaki verileri doğrudan işleyebilir ve içlerindeki karmaşık ilişkileri öğrenebilir, farklı ağlar arasında daha önceden keşfedilmemiş yeni ilişkiler kurabilir.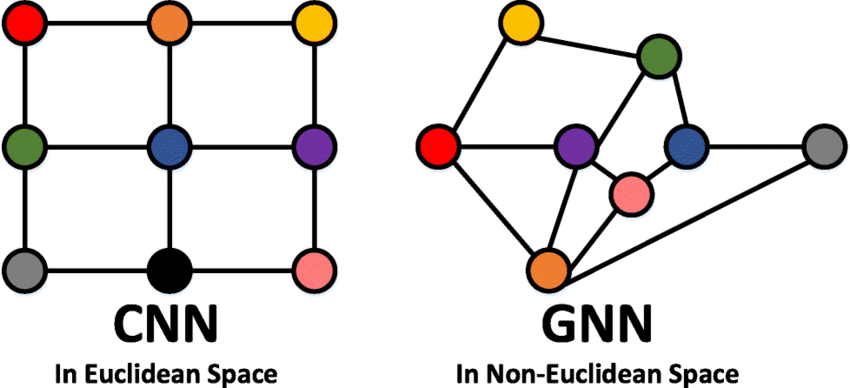
Şekil 3 : CNN ve GNN Algoritmalarının İlgilendiği Veri Tiplerinin Farkları(3)
GNN'lerin Temel Yapı Taşları Nelerdir?
- Graf (Graph): GNN'ler graf veri yapısı üzerinde çalışır. Bir graf, düğümler (nodes) ve kenarlar (edges) kümesinden oluşur. Düğümler verideki varlıkları (örneğin insanlar, moleküller, kelimeler) temsil ederken, kenarlar bu varlıklar arasındaki ilişkileri (örneğin arkadaşlıklar, kimyasal bağlar, anlamsal ilişkiler) temsil eder.
- Düğüm Özellikleri (Node Features): Her düğüm kendisini tanımlayan bir dizi özelliğe (örneğin yaş, atom numarası, kelime vektörü) sahip olabilirler. Bu özellikler düğümlerin temsil edilmesine ve GNN tarafından işlenmesine yardımcı olur.
- Kenar Özellikleri (Edge Features): Bazı graf yapılarında kenarlar da kendilerini tanımlayan özelliklere (örneğin ilişkinin türü, ağırlığı, yönü) sahip olabilirler. Bu özellikler düğümler arasındaki ilişkilerin daha ayrıntılı bir şekilde modellenmesine olanak tanır.
GNN'lerin Çalışma Aşamaları
GNN'ler, genellikle denetimli öğrenme veya yarı denetimli öğrenme yöntemleriyle eğitilir. Eğitim sürecinde, modelin parametreleri, graf yapısı ve düğüm/kenar özellikleri kullanılarak optimize edilir. Amaç, modelin belirli bir görevdeki performansını maksimize etmektir.
GNN'ler, temel olarak şu adımlarla çalışır:
- Mesaj Geçirme (Message Passing):
Her bir düğümün diğer komşu düğümlerinden mesaj (bilgi) alarak kendi temsilini (özellik vektörünü) zenginleştirmesini sağlar. Alınan bu bilgiler komşu düğümlerin mevcut temsillerinden ve aralarındaki kenarların özelliklerinden hesaplanır. Buradaki bilgi hesaplama fonksiyonu genellikle öğrenilebilir parametrelere sahip bir sinir ağıdır [örneğin çok katmanlı algılayıcı (MLP)].
- Toplama (Aggregation):
Her bir düğümün aldığı tüm mesajları birleştirerek tek bir temsil oluşturmasını sağlar. Burada kullanılan toplama fonksiyonu genellikle ortalama alma, toplama, maksimumu alma ya da dikkat mekanizması işlemleri kullanılarak çalıştırılır. Bu adım, düğümün komşularından gelen bilgileri özetlemesine yardımcı olur.
- Güncelleme (Update):
Her bir düğümün topladığı mesajları ve mevcut temsilini kullanarak kendi temsilini yenisiyle güncellemesini sağlar. Bu fonksiyon ise genellikle öğrenilebilir parametrelere sahip bir sinir ağıdır (örneğin MLP, RNN).
- Tekrarlama (Iteration):
Mesaj geçirme, toplama ve güncelleme adımlarının tüm graf yapısında bilgi yayılana kadar tekrarlanmasını sağlar (genellikle birkaç katman veya iterasyon tekrarlanır). Her tekrarda düğümler komşularından daha fazla bilgi toplar ve temsilleri daha zengin hale gelir. Bu tekrarlama süreci, GNN'lerin graf yapısındaki uzak bağımlılıkları yakalamasına olanak tanır.
- Çıktı (Output):
Son iterasyonunun ardından düğüm temsilleri, düğüm sınıflandırması, bağlantı tahmini veya graf sınıflandırması gibi çeşitli görevler için kullanılabilir. Çıktı katmanı genellikle öğrenilebilir parametrelere sahip bir sinir ağıdır ve göreve özgü bir şekilde tasarlanır.
Sonuç
Bu makalenin başında size sorduğumuz soruya cevap vermek gerekirse, şu anlık hayır. Ancak ilaç keşif sürecinde önemli bir rol oynadıklarını ve yeni ilaç adaylarının belirlenmesine yardımcı olduklarını biliyoruz. Biraz düşündüğümüzde transformatör algoritmalarının (anlam uzayları sayesinde) kelimeleri anlamlandırabildiği gibi moleküller arasındaki bağları anlamlandırabilen bir yapay zeka kulağa çok da fütüristik gelmiyor, öyle değil mi?
Grafik Sinir Ağları (GNN'ler) veri dünyasındaki karmaşık ilişkileri anlamlandırma ve bu ilişkilerden değerli bilgiler çıkarma konusunda çığır açan bir potansiyele sahiptir. Geleneksel yöntemlerin yetersiz kaldığı sosyal ağ analizi, öneri sistemleri, ilaç keşfi, trafik tahmini ve doğal dil işleme gibi birçok alanda GNN'ler güçlü bir çözüm sunar. GNN'lerin bu alanlardaki başarılı uygulamaları onların gelecekteki potansiyelini daha da heyecan verici hale getirmektedir.
GNN'lerin daha büyük ve karmaşık veri setlerini işleyebilme, açıklanabilirlik ve şeffaflık sunabilme, dinamik ve zamanla değişen grafları modelleyebilme yeteneklerinin gelişmesiyle birlikte, yapay zeka alanında yeni ufuklar açılacaktır. GNN'lerin diğer yapay zeka teknikleriyle entegrasyonu ile daha güçlü ve çok yönlü uygulamaların geliştirilmesine olanak sağlayacaktır.
GNN'ler insan zekasının ve merakının sınırlarını zorlamaya devam eden bir keşif. Ve bizler bu keşiflerin ilk anlarına şahit oluyoruz.
Referanslar:
- α-Methyldoppamine : https://en.wikipedia.org/wiki/%CE%91-Methyldopamine
- Graphs : https://adacomputerscience.org/concepts/struct_graph?examBoard=ada&stage=all
- Graph Neural Network and Some of GNN Applications: Everything You Need to Know : https://neptune.ai/blog/graph-neural-network-and-some-of-gnn-applications
-
 DEVAMI
DEVAMIBüyük Dil Modelleri (BDM) günümüzün en önemli teknolojilerinden biridir ve isminde de yer aldığı gibi gerçekten büyüklerdir. Ancak bu onların kusursuz olduğu anlamına gelmez. Bazen onlara sorduğunuz sorulara verdikleri yanıtlar ne dediklerini bilmiyormuş gibi görünür, çünkü gerçekten hiçbir şey bilmiyorlar. Büyük Dil Modellerinin tek gördüğü, istatistiksel olarak hangi kelimelerin birbiri ile daha alakalı olduğudur neyi ifade ettikleri değil. Bu da BDM’lerin en önemli sorunlarından biri olan halüsinasyona sebep olur.
Bir diğer sorun ise bir Büyük Dil Modeli eğitildikten kısa bir süre sonra bile güncelliğini yitirir. Her an yaşanan yeni bir olay veya yeni bir keşif sonrasında onları tekrar eğitemeyiz. Çünkü bu çok maaliyetli ve verimsiz bir yaklaşımdır. Yani adeta zamanda donup kalmış hem de sanki bir kapalı kutu gibidirler. Verdikleri bilgiyi nereden elde ettiklerini de zaten bilemeyiz. Bir kişiye güneş sistemimizde en çok uydusu olan gezegenin hangisi olduğunu sorsak ve bize yanıt olarak dese ki 10 sene önce çocukken bir dergide Jüpiterin 88 uydusu olduğunu gördüm vermesi gibidir. Bu bilginin kaynağını bilmiyoruz ve güncel değil.
Ve eğer Büyük Dil Modelimizin belirli bir alana özgü şekilde çok yüksek doğrulukla ve verimlilikle çalışmasını istersek, halihazırda bulunan BMD’ler bu isteğimizi karşılamaz. Çünkü genel amaçlı eğitilmişlerdir. Buna çözüm olarak onlara bu alana özgü veri setleri ile ince ayar (fine tuning) yapabiliriz.
Bu yöntem ne kadar maaliyetli bir iş olsada o alana özgü genel bakış açısını Büyük Dil Modeline sağlar. Ancak bu modellerin öncesinde çok büyük veri setleri ile eğitildiğini düşünürsek, ince ayar için kullandığımız veri seti onu bir görevde mükemmel yapmak için yeterli olmaz. Tüm bu problemleri azaltabilmek veya çözebilemek için 2020 yılında Facebook Research yaptığı araştırma sonucu almayla artırılmış üretim (RAG) yöntemini tanıttı. Bu yöntem ince ayar yapmaya göre oldukça düşük maaliyete sahiptir ve uygulaması da daha kolaydır. RAG’in birden çok yöntemi vardır ancak hepsinde genel mantık aynıdır. Girilen isteme göre bir sorgu elde edilir. Daha sonrada bu sorguyu kullanarak önceden belirlenmiş bilgi kaynaklarından en alakalı veriler getirilir. Bu getirilen veriler istemle birleşitirilerek Büyük Dil Modeline sunulur. Bu ise BDM’in güncel veya bağlama en yakın bilgiye sahip olmasını sağlar.
Sorgu (Query) ve İstem (Prompt) Nedir?
Yazının devamında bu iki kavramı oldukça sık göreceğiz. Bu yüzden başlangıçta ayrımı yapmamız iyi olacaktır. Kullanıcı Büyük Dil Modelinden bir yanıt almak için ona bazı sorular sormalı veya talimatlar girmelidir. Bu girdinin bütününe istem denir. Küçük bir kelime veya harf değişikliğinde bile yanıt tamamen farklı gelebilir. En uygun promptu bulma pratiğine istem mühendisliği (prompt engineering) denir. Sorgu ise sisteme RAG’i dahil ettiğimiz zaman devreye girer. Bu durumda Büyük Dil Modeli’ne kendi verdiğimiz istem dışında bir bağlam kazandırmak isteriz. Bu bağlam cevap beklenen konuda BDM’in sahip olmadığı güncel bir veri olabilir veya şirkete özel veriler olabilir. Belki binlerce farklı bilgi kaynağı arasından en alakalı verileri getirip prompta eklemek isteriz. Bu durumda bilgi kaynaklarını farklı algoritmalar ile taramak için bir sorgu inşa ederiz. Bu bazı durumlarda istem ile doğrudan aynı olabilir.
RAG Nasıl Çalışır?
Almayla artırılmış üretim sistemi daha küçük bir çok modül olarak tanımlanabilsede temelde iki ana aşaması vardır. Birincisi; elde etme aşaması (Retrieval phase) ikinci aşama ise üretim aşamasıdır (Generation phase). İlk aşamada daha önce inşa ettiğimiz sorguyu kullanarak tek veya birden fazla bilgi kaynağı arasından sorgu (query) ile semantik olarak veya matematiksel olarak en benzer olanlarını bulur ve getirir. Bu bilgi kaynakları web araması sonuçları, şirket dökümanları veya bir veritabanı olabilir.
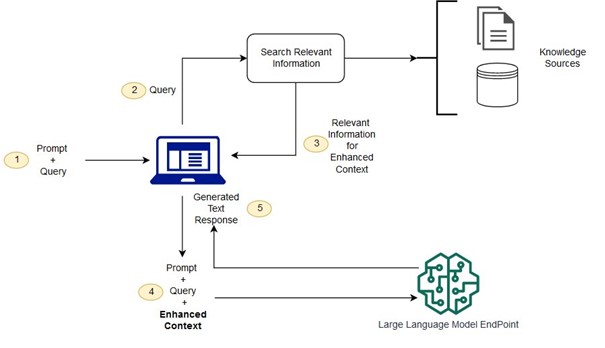
Şekil-1: Genel bir RAG Mimarisi
İkinci aşamaya üretim aşaması denmesinin nedeni, ilk aşamada elde ettiğimiz bağlamı veya bağlamları belirlenmiş bir formata göre isteme dahil ederiz. Bu üretilmiş yeni istem Büyük Dil Modeline verilir. Ve artık Büyük Dil Modeli bağlama bağlı kalarak daha tutarlı ve güncel bilgiler üretir.
RAG Aşamaları
Bir RAG sistemi bir önceki başlıkta belirttiğim gibi iki temel modülün altında daha küçük alt modüllerden oluşur bunlar; sorgu oluşturma, sorgu dönüştürme, yönlendirme, indexleme, elde etme ve üretim modülleridir. Bu modüllere sırasıyla kısaca değineceğim.
.png)
Şekil-2: RAG aşamaları diyagramıSorgu Oluşturma (Query Construction)
Almayla artırılmış üretim sistemlerinde ilk aşama sorgu oluşturmadır. İnsan tarafından oluşturulan istemden elde edilecek olan doğal dildeki sorgu, farklı veri kaynaklarının anlayabileceği bir formata dönüştürülür. Bu SQL tabanlı veritabanları için SQL sorguları veya vektör veritabanlarında kelime gömmeleri olabilir. Bu bölüm önemlidir çünkü bilgiyi veritabanından en optimum şekilde elde etmek için sorgunun doğru yorumlandığından emin olmamız gerekir.
Sorgu Dönüştürme (Query Translation)
Sorgu dönüştürme aşaması, doğal dildeki bir sorgunun, daha anlaşılır hale getirilmesi veya daha küçük, daha spesifik parçalara bölünmesi sürecini kapsar. Bu aşama, temel olarak iki önemli adım içerir. İlk adım, Sorgu Ayrıştırma (Query Decomposition) olarak bilinir ve burada orijinal sorgu, alt sorgulara ayrıştırılır veya yeniden formüle edilir. Bu sayede, sorgunun daha karmaşık ve çok yönlü yapısı, daha küçük ve yönetilebilir bileşenlere ayrılmış olur. Bu işlem sırasında kullanılan teknikler arasında Multi-query, Step-back ve RAG-Fusion gibi yöntemler bulunur.
İkinci adım ise Sahte Belgeler (Pseudo-documents) oluşturulmasıdır. Bu süreçte, sorguya yanıt olarak, olası cevapları temsil eden hipotez belgeleri oluşturulur. Bu belgeler, gerçekte var olmayan, ancak potansiyel olarak ilgili bilgileri içeren dokümanlar gibi düşünülebilir. Burada kullanılan HyDE yöntemi, bu tür belgelerin oluşturulmasını sağlar. Sonuç olarak, Sorgu Dönüşümü aşaması, bir sorguyu daha etkili bir şekilde işleyebilmek ve nihayetinde doğru cevabı bulabilmek için çeşitli dönüşüm ve ayrıştırma işlemlerini içerir.
Sorgu Oluşturma (Query Generation): Kullanıcının girdiği sorgudan, çeşitli alt sorgular türetilir. Bu alt sorgular, farklı bakış açılarını yakalayarak, kullanıcının niyetini tam olarak anlamaya çalışır. Böylece sorgunun daha kapsamlı bir şekilde ele alınması sağlanır.
Alt Sorgu Getirme (Sub-query Retrieval): Her alt sorgu için büyük veri setlerinden ve bilgi havuzlarından ilgili bilgiler toplanır. Bu adım, kapsamlı ve derinlemesine arama sonuçları elde etmek amacıyla yapılır.
Karşılıklı Sıralama Birleşimi (Reciprocal Rank Fusion): Getirilen dokümanlar, Reciprocal Rank Fusion (RRF) yöntemi kullanılarak birleştirilir. Bu yöntem, dokümanların sıralarını birleştirerek en alakalı ve kapsamlı sonuçları önceliklendirir, böylece en iyi yanıtları elde etmemizi sağlar.
Yönlendirme (Routing)
Yönlendirme (Routing) aşaması birden fazla veri kaynağı varken, gelen sorgunun hangi veritabanına veya bilgi kaynağına yönlendirileceğine karar verilmesini sağlar. Bu mantıksal yönlendirme ve anlamsal yönlendirme olarak çalışma şekline göre iki farklı şekilde yapılabilir.
.png)
Şekil-3: Yönlendirme örneği
Mantıksal Yönlendirme (Logical Routing): Bu yöntemde sorgunun yapısına bağlı olarak birden fazla veri kaynağı arasından hangisinin kullanılacağına mantıklı bir değerlendirme sonucu karar verilmesini ifade eder. Bu aşamada arzu edilirse bu seçme işlemi için de Büyük Dil Modeli kullanılabilir.
Anlamsal Yönlendirme (Semantic Routing): Bu yönlendirme metodunda ise mantıksal değil üretilmiş sorgunun anlamına göre çoklu veri kaynaklarından gelecek yanıtlar arasından hangisinin daha uygun olabileceğine karar verilmesidir. Bunu elde etmek için ise kelime gömmeleri (word embeddings) yani bir uzayda yön ve konumsal olarak anlam ifade eden vektörler kullanılabilir.
Kalan diğer aşamalar için girişte yaptığım tanımlama ile açıklamıştım. Kısaca özetlemek gerekirse Getirme (Retrieval) aşaması veri kaynağı seçildikten sonra ilgili dökümanları alıp listelemeyi içeriyor. Bu süreçte farklı sıralama (ranking) algoritmaları çalışabilir. İndeksleme (Indexing) aşamasında veriler önce parçalara (chunk) ayrılıp düzenleniyor, farklı formatlarda saklanıyor, alanına özel gömme teknikleri ile işleniyor ve doküman özetleri bir ağaç yapısında farklı seviyelere göre gruplandırılıyor. Son aşama olan üretimde (generation) istem için en uygun cevabı üretmek üzere çekilen dokümanlar ve yeniden yazılmış istemler kullanılarak yanıt elde edilir.
Reciprocal Rank Fusion (RRF)
Reciprocal Rank Fusion (RRF), birden fazla arama sonucunu birleştirerek tek bir sıralı sonuç kümesi oluşturmak için kullanılan bir algoritmadır. RRF, her bir arama sonucunun sıralamasına ters sıralama puanı atayarak çalışır. Bu puanlar daha sonra toplanır ve sonuçlar bu birleşik puanlara göre sıralanır. Birden fazla sorgunun paralel olarak çalıştırıldığı durumlarda, özellikle karma arama ve birden fazla vektör sorgusu gibi senaryolarda kullanılır. RRF, her bir sonuç listesindeki öğelerin orijinal sıralamasını dikkate alarak, birden fazla listede üst sıralarda yer alan öğelere daha yüksek önem verir. Bu, son sıralamanın genel kalitesini ve güvenilirliğini artırır. Şöyle bir örnek verilebilir: İnternette aynı şeyi aradığınızda, farklı arama motorları veya yöntemleri size farklı sıralamalarda sonuçlar sunar. RRF, bu farklı sıralamalardaki sonuçları alır ve en üstte olanları daha önemli kabul ederek, hepsini birleştirir. Böylece, en alakalı sonuçlar yeni oluşturulan listenin en başında yer alır. Bu yöntem, farklı kaynaklardan gelen sonuçları tek bir listede en iyi şekilde sıralamak için kullanılır.
LangChain Kullanarak Basit RAG Oluşturmak
LangChain, Büyük Dil Modelleri ve diğer AI araçlarını kullanarak çeşitli görevler gerçekleştirmek için bir zincir veya akış oluşturmanıza olanak tanıyan bir araçtır. Özellikle, doğal dil işlemi ve metin üretimi gibi görevlerde, büyük dil modellerini daha verimli ve hedefe yönelik kullanmak için araçlar sunar. LangChain, veri sorgulama, belge arama, özetleme ve karar destek sistemleri gibi uygulamalarda kullanılır ve genellikle BDM’leri daha karmaşık iş akışlarına entegre etmek için kullanılır. Basitten karmaşığa bir çok sistem için kullanılabilir. RAG sistemi oluşturmak için LangChain dökümantasyonundan basitçe bir kod örneği aşağıya ekledim.
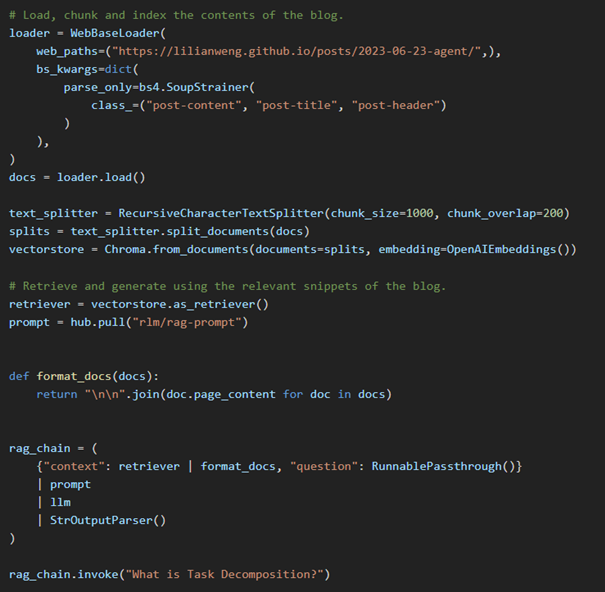
Şekil-4: LangChain ile RAG oluşturma koduSonuç
BDM'lerin zamanla güncelliğini yitirmesi ve halüsinasyon gibi sorunlara yol açabilmesi, bu modellerin pratik uygulamalarda karşılaştığı başlıca sorunlar arasındadır. RAG, bu sorunlara çözüm sunmak amacıyla ortaya çıkmış bir yöntemdir ve ince ayar yapmaya kıyasla daha düşük maliyetli bir alternatif olarak öne çıkmaktadır. RAG'in işleyişi, çeşitli aşamalar ve modüller üzerinden detaylı bir şekilde açıklanmış, özellikle sorgu oluşturma, dönüştürme ve üretim aşamaları üzerinde durulmuştur. LangChain gibi araçlar sayesinde, RAG sistemleri basit bir şekilde oluşturulabilir ve entegre edilebilir. Bu çalışmalar, BDM'lerin daha verimli ve doğru bir şekilde kullanılabilmesi için önemli bir adımı temsil etmektedir.
Referanslar
1- Amazon Web Services. What is RAG (Retrieval-Augmented Generation?)
2- Yöndem, D. Retrieval Augmented Generation'a Giriş [Video].
3- IBM Research. What is retrieval-augmented generation?
4- A Comprehensive Guide to RAG Implementations. NoCode.ai Newsletter.
5- Singh, S. Mastering RAG: Advanced Methods to Enhance Retrieval-Augmented Generation.
6- Build a Retrieval Augmented Generation (RAG) App, LangChain Dökümantasyonu
7- Relevance scoring in hybrid search using Reciprocal Rank Fusion (RRF), Microsoft -
 DEVAMI
DEVAMIYapay zekanın en heyecan verici ve yenilikçi alanlarından biri olan Çekişmeli Üretici Ağ (Generative Adversarial Networks, GAN), iki sinir ağı modelinin birbirine karşı rekabet etmesine dayanan benzersiz bir öğrenme yöntemidir. Bu modellerden biri "üreteç" (generator) diğeri ise "ayrımcı" (discriminator) olarak adlandırılır. Üreteç, gerçekçi veri üretmeye çalışırken, ayrımcı ise bu verinin sahte mi yoksa gerçek mi olduğunu ayırt etmeye çalışır. Bu rekabetçi süreç sayesinde GAN'lar, görüntüler, sesler ve daha fazlası gibi son derece gerçekçi çıktılar üretebilir.
2014 yılında Ian Goodfellow ve ekibi tarafından geliştirilen bu teknoloji, yapay zeka ve makine öğrenimi dünyasında adeta bir devrim meydana getirmiştir. Şirketimiz de bu alandaki en yenilikçi yaklaşımlardan biri olan GAN mimarisini kullanarak projelerimizi bir adım öne taşımaktadır.
Bu yazımızda, GAN'ın ne olduğunu, nasıl çalıştığını ve neden bu kadar önemli olduğunu keşfedeceğiz. GAN teknolojisinin sunduğu bu heyecan verici dünyaya bir adım atarken, sizlere de farklı bir dünyanın kapılarını aralamayı amaçlıyoruz.
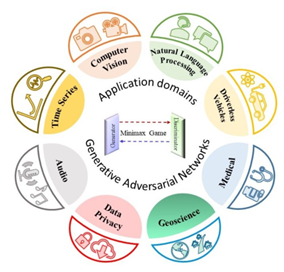
Şekil-1 GAN uygulama alanları
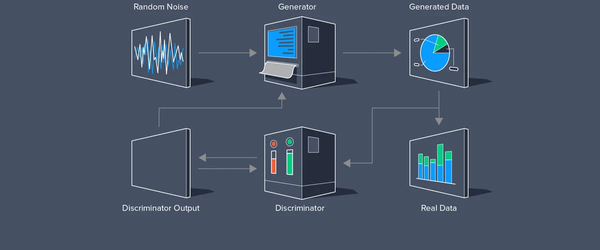
GAN Nedir?Çekişmeli Üretici Ağ (GAN), bir derin öğrenme mimarisidir. Bu mimari, belirli bir eğitim veri kümesinden daha özgün yeni veriler üretmek amacıyla iki sinir ağını birbirleriyle rekabet edecek şekilde eğitir. Örneğin, mevcut bir görüntü veritabanından yeni görüntüler veya bir şarkı veritabanından orijinal müzik üretebilirsiniz. GAN'lere "çekişmeli" adı verilmesinin nedeni, iki farklı ağı eğitip birbiriyle yarıştırmasıdır. Ağlardan biri, giriş verileri örneği alarak bunu olabildiğince değiştirerek yeni veriler üretir. Diğer ağ ise, üretilen veri çıktısının orijinal veri kümesine ait olup olmadığını tahmin etmeye çalışır. Başka bir deyişle, tahminde bulunan ağ, üretilen verilerin sahte mi yoksa gerçek mi olduğunu belirler. Sistem, tahminde bulunan ağın sahte ile orijinal veriyi ayırt edemez hale gelene kadar sahte veri değerlerinin daha yeni ve geliştirilmiş sürümlerini üretir.
GAN'ların Temel Yapısı?
GAN'ların temel bileşenleri iki ana bileşenden oluşur: Generator (Üreteç) ve Discriminator (Ayrımcı). Üreteç, rastgele girdi verilerini alarak bu verileri gerçekçi görseller veya veriler üretmek amacıyla işler. Ayrımcı ise hem gerçek verileri hem de üreteç tarafından üretilen sahte verileri alır ve bu verilerin gerçek mi yoksa sahte mi olduğunu ayırt etmeye çalışır. Bu iki bileşen, birbirleriyle etkileşime girerek ve sürekli olarak kendilerini geliştirerek çalışır. Üreteç, ayrımcının sahte verileri doğru bir şekilde tespit edememesi için daha iyi ve daha gerçekçi veriler üretmeye çalışırken, ayrımcı da bu sahte verileri daha iyi tespit edebilmek için kendini geliştirir. Bu rekabetçi süreç, her iki bileşenin de zamanla daha yetenekli hale gelmesini sağlar.
Şekil-2 Temel GAN Mimarisi
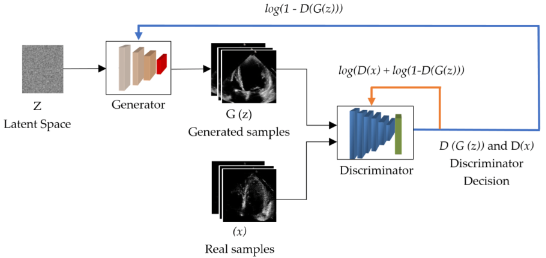
GAN'ların Çalışma Prensibi?
Çekişmeli üretici ağ (GAN), iki derin sinir ağından oluşan bir sistemdir. Bir taraf üretici ağ, diğer taraf ise ayırıcı ağdır. Bu sistem, üretici ağın yeni veri üretmeye çalıştığı ve ayırıcı ağın üretilen verinin gerçek mi yoksa sahte mi olduğunu belirlemeye çalıştığı bir çekişmeli senaryo üzerine kuruludur.
GAN'ın çalışma prensibi aşağıdaki adımlarla özetlenebilir:1. Üretici sinir ağı, eğitim setini analiz ederek veri özniteliklerini tanımlar.
2. Ayırıcı sinir ağı, ilk eğitim verilerini analiz ederek öznitelikler arasında bağımsız olarak ayrım yapar.
3. Üretici ağ, belirli özniteliklere gürültü ekleyerek bazı veri özniteliklerini değiştirir.
4. Değiştirilmiş verileri ayırıcı ağa ileterek ayırıcı ağın oluşturulan çıktının orijinal veri kümesine ait olma olasılığını hesaplamasını sağlar.
5. Ayırıcı ağ, bir sonraki döngüde üretici ağa kılavuzluk yaparak gürültü vektörünün rastgeleleştirilmesini azaltmaya çalışır.
6. Üretici ağ, ayırıcı ağın hata olasılığını maksimize etmeye çalışırken, ayırıcı ağ ise hata olasılığını minimize etmeye çalışır.
7. Eğitim iterasyonları boyunca, hem üretici ağ hem de ayırıcı ağ sürekli olarak değişime uğrar ve çekişmeli bir şekilde gelişir.
8. Eğitim süreci dengeye ulaştığında, ayırıcı ağ artık sentezlenmiş verileri tanıyamaz hale gelir ve eğitim sona erer.
GAN Türleri Nelerdir?1. Standard GAN (SGAN): İlk olarak 2014 yılında Ian Goodfellow ve arkadaşları tarafından tanıtılan temel GAN yapısı. Üretici ve ayırıcı ağların temel çekişmeli yapıya sahip olduğu versiyonudur.
2. Conditional GAN (CGAN): Şartlı GAN, GAN'ın üretici ve ayırıcı ağlarını, belirli bir koşula (genellikle etiket veya sınıf bilgisi) göre eğittiğimiz versiyonudur. Bu yöntem, belirli özelliklere sahip örneklerin sentezlenmesinde veya dönüşümünde kullanışlıdır.
3. Deep Convolutional GAN (DCGAN): Derin evrişimli GAN, evrişimli sinir ağları (CNN'ler) ile güçlendirilmiş bir GAN türüdür. Görüntü verileri için daha stabil ve kaliteli sonuçlar üretmeye odaklanır.
4. Wasserstein GAN (WGAN): WGAN, GAN'ın eğitim sürecinde yaşanan bazı problemleri çözmek için geliştirilmiştir. Eğitim stabilitesini artırmak ve gradient sorunlarını önlemek için Wasserstein mesafe ölçüsü kullanılır.
5. Progressive GAN: İlk olarak NVIDIA tarafından önerilen bu GAN türü, aşamalı olarak yüksek çözünürlüklü görüntüler üretmek için eğitilir. Başlangıçta düşük çözünürlükte başlayıp zamanla yüksek çözünürlüklü görüntüler elde etmek için ağın aşamalı olarak büyütülmesini içerir.
6. StyleGAN ve StyleGAN2: NVIDIA tarafından geliştirilen bu GAN türleri, yüksek kaliteli ve yüksek çözünürlüklü görüntü sentezi için stil transferi tekniklerini kullanır. Özellikle yüz ve insan görüntüleri için çok başarılı sonuçlar verir.
7. CycleGAN: Döngüsel GAN, farklı alanlar arasında çeviri yapmak için kullanılır. Örneğin, bir tarzdan başka bir tarza resim veya video dönüşümü için kullanılabilir.
8. Self-Attention GAN (SAGAN): Kendi dikkat GAN'ı, dikkat mekanizmalarını kullanarak uzak bağlantıları ele alır ve daha büyük ve daha karmaşık veri kümelerinde daha iyi sonuçlar sağlar.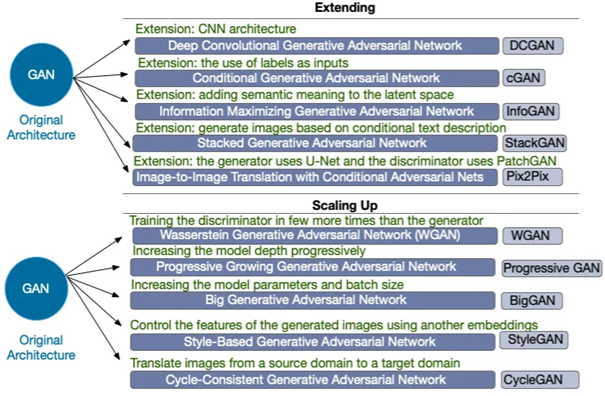
Şekil-3 Temel GAN türleriBu yazımızda Style GAN türünden bahsedeceğiz.
Style GAN nedir?
Style GAN (Stil Uyumlu Üretici Ağ), NVIDIA araştırmacıları tarafından geliştirilmiş bir GAN türüdür. Bu model, geleneksel GAN'lardan farklı olarak, sentezlenen görüntülerin stil ve içerik kontrolünü ayrı ayrı yönetebilme yeteneği ile öne çıkar. Üretici ağ, girdi olarak rastgele bir vektör ve stil vektörlerini (latent space) alır. Stil vektörleri, oluşturulan görüntünün renk, dokular ve diğer görsel özellikleri üzerinde doğrudan kontrol sağlar. Bu sayede, Style GAN hem görsel kaliteyi artırır hem de daha gerçekçi ve çeşitli görüntüler üretme yeteneği kazandırır.

Şekil-4 Style GAN ile üretilmiş fotoğraflar
Latent Space Nedir ve Style GAN'da Nasıl Kullanılır?Latent Space, görüntünün özelliklerini temsil eden soyut bir uzaydır. Style GAN'da, bu uzay rastgele vektörler (latent vector) ile temsil edilir. Bu vektörler, görüntünün stil veya özelliklerini belirlemek için kullanılır. Örneğin, bir latent vektör ile saç rengi, yüz ifadesi veya arka plan gibi özellikler kontrol edilebilir.
Mapping Network ve Synthesis Network Yapısı
Style GAN'da iki ana ağ yapısı bulunur:
1. Mapping Network (Eşleme Ağı): Bu ağ, rastgele latent vektörleri alır ve onları görüntü sentezi için uygun bir uzaya dönüştürür. Mapping network, latent vektörlerin daha düzenli bir şekilde dağılmasını sağlayarak, görüntü sentezinin daha tutarlı ve kontrol edilebilir olmasını sağlar.
2. Synthesis Network (Sentez Ağı): Bu ağ, Mapping Network tarafından üretilen latent vektörleri alır ve bu vektörleri gerçekçi görüntülere dönüştürür. Synthesis network, her katmanda görüntünün detaylarını ve yapısal özelliklerini iyileştirir, böylece sonuç olarak daha gerçekçi ve detaylı görüntüler elde edilir.Bu yapılar, Style GAN'ın genişletilmesi ve optimize edilmesi için temel oluşturur. Geliştiriciler, bu yapıları kullanarak özgün ve yenilikçi görseller oluşturabilirler, bu da Style GAN'ı sanat, moda ve dijital içerik oluşturma gibi çeşitli alanlarda kullanılabilir hale getirir.
GAN ve Style GAN Uygulama Alanları
1. Sanat ve Yenilikçi Endüstriler: Style GAN, sanatçıların yenilikçi dijital sanat eserleri oluşturmalarına olanak tanır, yüksek çözünürlüklü ve gerçekçi görseller elde etmelerini sağlar.
2. Moda Tasarımı: Moda endüstrisinde, yeni desenler, kumaş dokuları ve giysi stilleri oluşturmak için GAN'lar ve Style GAN kullanılır. Bu yöntem, moda tasarımcılarının inovasyon kabiliyetlerini sınırlamadan yeni trendler ve koleksiyonlar geliştirmelerine yardımcı olur.
3. Oyun Geliştirme: GAN teknolojileri, oyun geliştiricilerinin oyun dünyalarını ve karakterleri oluşturmasına yardımcı olur, daha gerçekçi ve çeşitli görseller sunmalarını sağlar.
4. Tıp ve Sağlık:-
- Medikal Görüntüleme: GAN'lar, MRI ve CT taramaları gibi medikal görüntüleme tekniklerinde kullanılarak, görüntüleri iyileştirebilir veya yeniden oluşturabilir, doktorların doğru teşhis koymasına yardımcı olabilir.
- Cerrahi Simülasyonlar: GAN'lar, karmaşık cerrahi prosedürlerin simülasyonları için kullanılabilir, cerrahi eğitimde pratik yapma imkanı sunar.
5. Makine ve Otomotiv Endüstrisi: GAN'lar, ürün tasarımı ve optimizasyon süreçlerinde kullanılarak, yeni parça ve bileşenlerin tasarımını iyileştirebilir, makine ve otomotiv endüstrilerindeki inovasyon süreçlerine katkıda bulunabilir.
6. Eğitim ve Simülasyon: GAN'lar, eğitim simülasyonları ve sanal laboratuvar ortamları oluşturmak için kullanılabilir, öğrencilerin pratik yapmalarını sağlar, teorik bilgilerini uygulamaya dökmelerine yardımcı olur.
Referanslar
1. https://www.innodeed.com/wp-content/uploads/2022/09/GAN-1170x640.png
2. https://cdn1.ntv.com.tr/gorsel/IKHMHEUbe0et1mQm8yWUUg.jpg?width=1000&mode=both&scale=both&v=1545216985506
3. Evaluating Synthetic Medical Images Using Artificial Intelligence with the GAN Algorithm. https://www.mdpi.com/2213968
4. https://towardsdatascience.com/generative-adversarial-networks-gans-a-beginners-guide-f37c9f3b7817
5. Ten Years of Generative Adversarial Nets (GANs): A survey of the state-of-the-art. https://www.researchgate.net/publication/373551906_Ten_Years_of_Generative_Adversarial_Nets_GANs_A_survey_of_the_state-of-the-art.
6. GAN nedir? - Çekişmeli Üretici Ağlara Ayrıntılı Bakış - AWS (amazon.com)
7. Çekişmeli Üretici Ağlar (GAN). Çekişmeli üretici ağlar, 2014 yılında… | by Burcu Koca | Deep Learning Türkiye | Medium
8. 942990 (dergipark.org.tr) -
-
 DEVAMI
DEVAMIBu blog yazımızda, ilkokul çağındaki çocuklardan teknik konularda çalışan birçok profesyonele kadar geniş bir yelpazede etkisini hissettiren büyük dil modellerinden bir nebze bahsedeceğiz. Gerçi büyük bir derya deniz olan bu konu ne kadar özetlenebilir sorusu hepimizin aklına gelebilir. Burada amacımız deniz kenarında gezintiye çıkmış birine bir nebze martıların seslerini dinleterek bir bakış açısı vermektir. Ayrıca kısaca tarihi serencamından da bahsederek kullanım alanları, çalışma mekanizması, teknik bazı terimleri ve örnek bir kod vererek çalışmasından bahsedilecektir.
Büyük Dil Modelleri Nedir ve Kullanım Alanları Nelerdir?
Doğal dil işleme, dil ile ilgili görevleri yerine getirmek için kullanılan yapay zeka alanıdır ve halihazırda hayatımızda yer almaktadır. Bu sistemler, belli bir düzeyde istenilen görevleri yerine getirebiliyor ancak yeterince iyi değillerdi. 2017 yılında Google Research ekibi tarafından, dil tercümesini daha iyi hale getirmek amacıyla yayımlanan “Attention is All You Need” makalesi, bu görevleri çok daha iyi şekilde yapabilen büyük dil modellerinin gelişimi için kapı araladı. Daha sonra, artan işlem gücü ve metinsel verilerle birlikte, yine Google tarafından geliştirilen ve Attention mekanizmasını kullanan BERT, yüksek parametre sayılarına sahip ve denetimsiz ön eğitimden geçmiş OpenAI’ın GPT modelleri bu gelişimi sürdürdü.Büyük dil modelleri, internet, kitaplar, makaleler ve video transkriptleri gibi farklı kaynaklardan elde edilmiş metinsel verilerle eğitilmiş, çok büyük sayıda parametreye sahip olan gelişmiş derin öğrenme modelleridir. Çok farklı Doğal Dil İşleme (DDİ) görevleri üzerinde eğitilen bu gelişmiş modeller, temelde aldıkları metinsel girdiye dayanarak sıradaki kelimeyi tahmin ederler.
Büyük dil modellerinin uygulama alanları çok daha geniş bir yelpazeyi kapsar. İnsanlarla etkileşim kurma yeteneği, doğal ve anlamlı diyaloglar gerçekleştiren sohbet botlarında en belirgin şekilde kendini gösterir. Bu botlar, müşteri hizmetlerinde, eğlence amaçlı sohbetlerde, eğitim materyallerinde kullanılabilir. Büyük dil modellerini kullanarak, reklamlar, blog yazıları, sosyal medya paylaşımları gibi farklı içerik türleri oluşturmak mümkündür. Belirli bir konuda özel dil modellerini eğiterek içeriğin kalitesi, akıcılığı ve özgünlüğü artırılabilir. Metinlerde yer alan duygusal tonu (pozitif, negatif, nötr) ve anlatılan konuyu analiz eden büyük dil modelleri, müşteri memnuniyetini ölçmede, sosyal medya trendlerini takip etmede, ve hatta reklam kampanyalarının etkisini değerlendirmede kullanışlıdır.
Uzun metinlerden özetler üretilen büyük dil modelleri, önemli bilgileri içeren, orijinal metnin özünü yansıtandır. Bu özellik, akademik araştırmada, özetlerin ve raporların oluşturulmasında faydalı olarak kullanmak mümkündür. Büyük dil modelleri, programlama dillerinde kod parçaları üretme yeteneğine de sahiptir. Bu yetenek, kod yazma süreçlerini kolaylaştırabilir, hata oranlarını azaltabilir ve kodlama yeteneği olmayan kişilerin de yazılım geliştirmelerine olanak tanıyabilir.Bunlara ek olarak farklı diller arasında çeviri yapma konusunda büyük dil modelleri oldukça başarılıdır.
Büyük dil modelleri nasıl çalışır?
Tokenizasyon
Bilgisayarlar verileri bizimle aynı şekilde algılamaz; onlar yalnızca sayıları (1 ya da 0) görür. Bu yüzden, yapay zeka modeline eğitim sırasında veya yürütme sırasında verilen metinsel verilerin sayılarla ifade edilmesi gerekir. Bu amaçla metinler önce tokenlara ayrılır. Tokenlar, büyük metinsel verilerin daha küçük ve anlamlı parçalara bölünmesidir. Bu işleme tokenizasyon denir. Örneğin OpenAI’ın kullandığı tokenizer, “ILGE yapay zeka” metnini aşağıdaki şekilde 6 farklı token’a ayırır. Kelime Gömmeleri (Word Embeddings)
Kelime Gömmeleri (Word Embeddings)
Bir önceki aşamada token haline getirilen veriler, bu aşamada matematiksel olarak anlamlı vektörlere dönüştürülür. Bu vektörler, yakınlık ve aralarındaki açı gibi faktörlerle kelimelerin sadece sayısal olarak ifade edilmesini sağlamakla kalmaz, aynı zamanda birbirleri arasındaki ilişkileri de temsil eder. Bu aşamalar, dil işleme alanının temel adımlarından biri olup, büyük dil modellerinden çok daha önce bu alana kazandırılmıştır. Kelimeleri vektörleştirirken, birbirleriyle olan bağlamlarının da öğrenilmesi için, cümledeki boşlukları dolduran, kelimenin çevresindeki diğer kelimeleri tahmin eden ve buna benzer görevlerle derin öğrenme teknikleri kullanılır. Bu öğrenme sayesinde semantik olarak birbirine yakın kelimeler daha yakın vektörlerde yer alırken, zıt anlamlı kelimeler ise karşıt konumlarda bulunur.Pozisyonel Kodlama (Positional Encoding)
Büyük dil modelleri, kelime dizilerini işlerken sadece kelimelerin anlamlarını değil, aynı zamanda kelimelerin sıralarını da dikkate almalıdır. Fakat kelime vektörleri (embeddings) kendi başlarına sıra bilgisini taşımazlar. Örneğin, "Ali okula gitti." ve "Gitti okula Ali." cümleleri aynı kelimeleri içermesine rağmen farklı cümlelerdir. Bu nedenle, modellerin bu tür sıra farklılıklarını anlaması için pozisyonel kodlama kullanılır.
Şekil-1 Örnek bir pozisyonel kodlamaPozisyonel kodlama, her tokenın pozisyonunu matematiksel bir vektörle ifade ederek, tokenın cümle içindeki sıralı yerini belirginleştirir. Bu işlem genellikle sinüs ve kosinüs fonksiyonları kullanılarak yapılır, çünkü bu fonksiyonlar periyodik oldukları için farklı pozisyonlarda benzersiz ancak ölçeklenebilir kodlamalar sağlar.
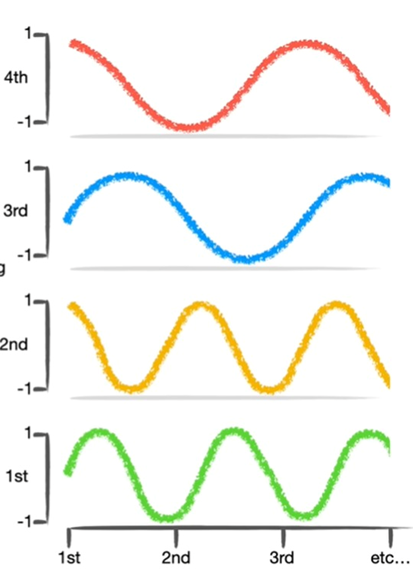
Şekil-2 Pozisyonel kodlama için sinüs/kosinüs fonksiyonlarıÖz Dikkat Mekanizması (Self Attention Mekanizması)
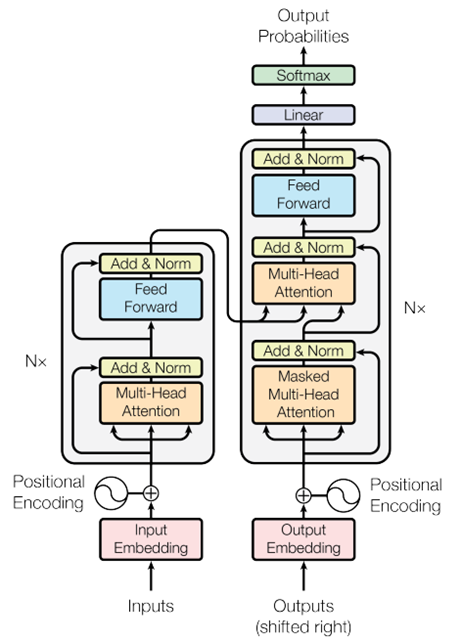
Biz insanlar için “Pizza fırından çıktı ve onun tadı güzeldi!” cümlesinde tadı güzel olan şeyin fırın değilde pizza olduğunu anlamak kolaydır, ancak makineler için aynı şey söz konusu değildir. Self attention daha uzun dizilerin anlamlı bir şekilde işlenmesini sağlayan ve büyük dil modellerini bu kadar güçlü kılan Transformer mimarisinin yapıtaşı olan mekanizmadır. Dizi içinde bulunan vektörlerin her biri diğer vektörlerle ilişkilerini değerlendirerek, her kelimenin cümle içindeki önemini ve bağlamını belirler.
Şekil-3 Transformer model mimarisiÖz dikkat mekanizmasında anahtar (key), değer (value) ve sorgu (query) kavramları, veriler arasındaki ilişkileri modellemek için kullanılır. Bu değerler eğitim sırasında öğrenilen bir dizi ağırlık ile vektörün çarpımı sonucu elde edilir. Bu sayede her kelime için bir sorgu vektörü oluşturulur. Bu vektör, diğer kelimelerle olan ilişkileri belirlemek için kullanılır. Daha sonra her kelime için bir anahtar vektörü üretilir. Bu anahtarlar, diğer kelimelerin sorguları ile karşılaştırılarak her kelimenin birbirine olan etkisinin derecesini belirler. Değer ise sorgu ile uyumlu anahtarlar bulunduğunda, bu anahtarlara bağlı değerler önem derecelerine göre toplanarak kelimenin yeni, güncellenmiş bir temsilini oluşturur.
Bir cümledeki her kelime için, öz dikkat mekanizması bu kelimenin diğer kelimelerle olan ilişkisini hesaplar. Her bir kelimenin sorgu vektörü, diğer tüm kelimelerin anahtar vektörleri ile bir dizi skor (dikkat skoru) hesaplamak için çarpılır. Bu skorlar softmax fonksiyonu ile normalize edilir, böylece her bir kelimenin diğer kelimeler üzerindeki etkisi bir olasılık dağılımı olarak ifade edilir.
Normalize edilmiş skorlar daha sonra ilgili değer (value) vektörleri ile çarpılır ve sonuçlar toplanarak her kelime için yeni bir vektör (dikkat çıktısı) oluşturulur. Bu yeni vektörler, kelimelerin cümle içindeki anlamını ve bağlamını daha iyi yansıtan, zenginleştirilmiş temsillerdir.
Çok Başlı Dikkat (Multi-Head Attention)
Transformer mimarisinin önemli bir parçası olan çok başlı dikkat, birden fazla dikkat başlığının bir arada kullanılması ile ortaya çıkar. Bu yapının çalışma mantığını anlamak için CNN’lerdeki filtreler düşünülebilir. Farklı filtreler görseldeki farklı özellikleri yakalar. Çok başlı dikkat’te de durum benzerdir. Farklı ağırlıklara sahip birçok dikkat başlığı (Self Attention) kullanılarak cümlenin farklı yerlerine odaklanılır. Bu başlıklar, cümlenin farklı bölümlerindeki ilişkileri öğrenir ve tespit eder.
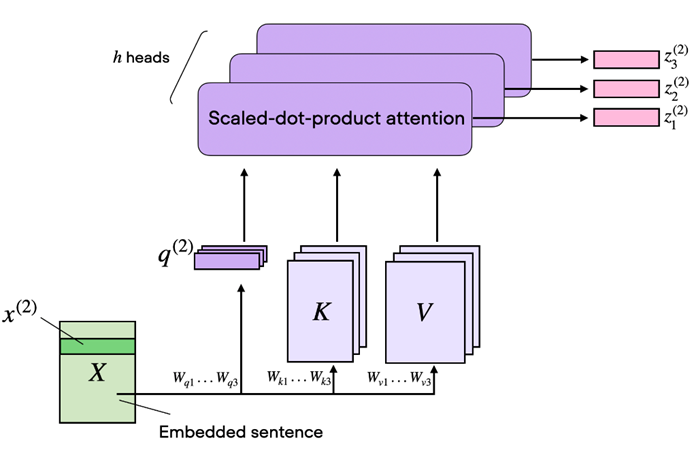
Şekil-4 Çok başlı dikkat katmanının yapısı
Maskelenmiş Çok Başlı Dikkat (Masked Multi-Head Attention)
Maskelenmiş çok başlı dikkat, dil modellemesinde özellikle önemlidir. Bu mekanizma, modelin sadece önceki kelimelere bakarak bir sonraki kelimeyi tahmin etmesini sağlar. Maskelenmiş çok başlı dikkat, gelecekteki kelimeleri maskeleyerek, modelin gelecekteki bilgilere erişimini engeller. Bunun amacı dil modeli oluştururken her adımda sadece önceki kelimeleri kullanarak tahmin yapmayı mümkün kılar. Örneğin, bir cümleyi kelime kelime üretirken modelin ilerideki kelimeleri bilmemesi gerekir ve bu mekanizma bunu sağlar.Dikkat çıktıları elde edildikten sonra topla ve normalleştir (Add & Norm) katmanı, iki temel işlemi içerir. Artık Bağlantı (Residual Connection) girişe orijinal girdiyi ekler ve derin modellerde gradyanların daha etkili bir şekilde geri yayılmasını sağlar ve daha derin katmanların öğrenmesini kolaylaştırır. Katman Normalizasyonu (Layer Normalization) ise girdinin her bir bileşenini normalize eder. Sonuç olarak modelin daha hızlı ve kararlı öğrenmesini sağlar.
Topla ve normalleştir katmanının ardından, ileri besleme (Feed Forward) katmanı devreye girer. İleri besleme katmanı, her pozisyon için bağımsız olarak çalışan tam bağlantılı bir sinir ağıdır ve genellikle iki lineer dönüşümden ve bir aktivasyon fonksiyonundan oluşur. Bu katman, modelin daha karmaşık ve soyut temsil seviyeleri öğrenmesini sağlar. İleri besleme katmanından elde edilen çıktı, tekrar topla ve normalleştir katmanına gönderilir ve ardından doğrusal katmanına geçer.
Son olarak, Lineer ve Softmax katmanları uygulanır. Lineer katmanı, modelin çıktısını sınıflandırma için uygun bir forma dönüştürür. Softmax katmanı ise modelin her bir olasılıkla ilgili tahminlerini normalize eder ve olasılık dağılımı elde edilir. Bu aşamaların sonunda, büyük dil modeli, girdiye dayalı olarak en olası kelime veya kelime dizisini üretmiş olur.
Büyük Dil Modelini İnce Ayarlama (Fine-Tuning)
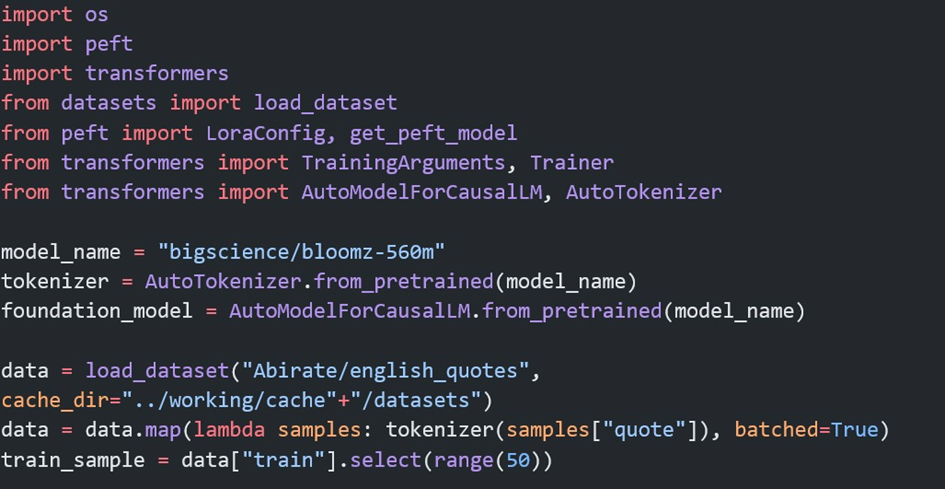
Bir projeye başlarken önce problemimizi belirleriz. Problemi iyi anladıktan sonra, çözüm için en iyi yöntemin büyük dil modelleri olduğu kanısına varabiliriz. Bir büyük dil modelini sıfırdan üretip onu eğitecek kadar çok veriye ve hesaplama gücüne ulaşmanın ne kadar zor olduğunun farkındayız. Bu yüzden ilk yapmamız gereken şey, açık kaynaklı veya kapalı kaynak dil modellerini problemimiz üzerinde test etmek olacaktır. Açık kaynaklı bir modeli kendi sistemimizde veya bir bulut servisinde çalıştırabiliriz. Kapalı kaynak sistemlerini ise kullanım bedeli ödeyerek projelerimize dahil ederiz. İnce ayar düşünmeden önce sistem mesajını optimize etmemiz gerekir; buna prompt mühendisliği denir. Eğer bu durum sonrasında hala istediğimiz sonuçlardan uzak isek, halihazırda ince ayar yapılmış büyük dil modellerini arayıp denemeliyiz. Örnek olarak bu tür modellere Huggingface, Kaggle vb sitelerden ulaşabiliriz. Tüm bu aşamalardan sonra hala olumlu sonuç yoksa, problemimize uygun ince ayar yöntemini seçer, uygun veriyi toplar ve ince ayar için eğitime başlarız. Güncel olarak LoRA ve QLoRA ile ince ayar yapmak performans ve kolaylık açısından çok popülerdir.LoRA ile İnce Ayar
LoRA ile ince ayarın nasıl yapıldığı hakkında görece olarak basit olan ve eğitimi daha kolay olan bir model üzerinde bir Kaggle kullanıcısının paylaştığı kodu inceleyebilirsiniz.
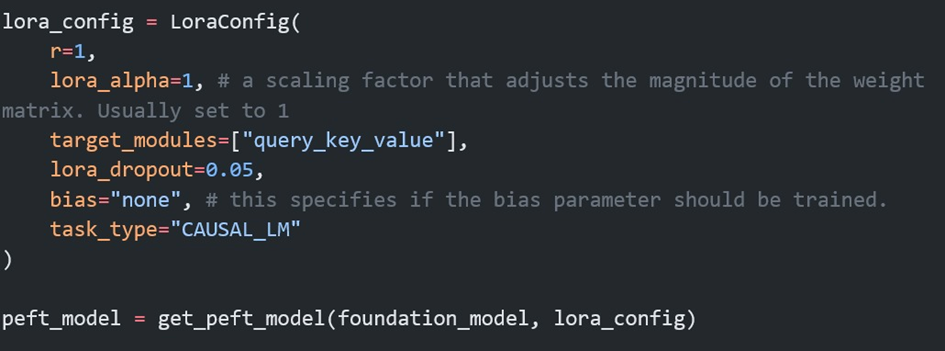
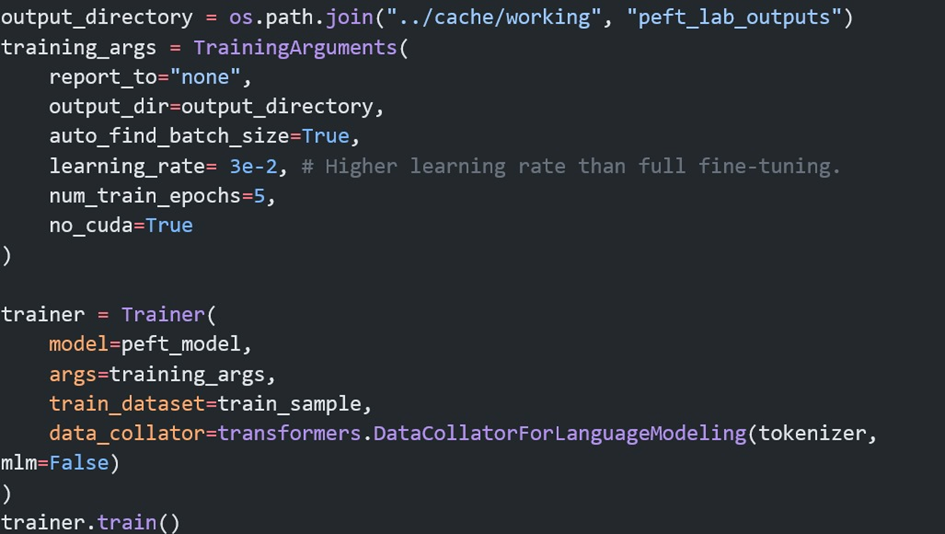
Sonuç:
Büyük dil modelleri, Doğal Dil İşleme alanında çığır açan yapay zeka sistemleridir. Bu modeller, geniş veri kümeleri üzerinde eğitilerek, insan benzeri metin oluşturma, çeviri, özetleme ve daha birçok dil tabanlı görevleri yerine getirebilir. BDM'lerin temel yapı taşları tokenizasyon, kelime gömmeleri, pozisyonel kodlama ve öz dikkat mekanizması gibi tekniklerdir. Özellikle 2017 yılında Google tarafından geliştirilen Transformer mimarisi, bu modellerin performansında büyük bir sıçrama sağlamıştır. Transformer'ların çok başlı dikkat mekanizması, dilin karmaşık yapısını anlamada ve metinlerin bağlamını doğru bir şekilde işlemede kritik bir rol oynar.
BDM'ler, müşteri hizmetlerinden, içerik oluşturma ve programlamaya kadar geniş bir yelpazede kullanılır. İnce ayar (fine-tuning) teknikleri, bu modellerin belirli görevler için daha uygun hale getirilmesini sağlar. LoRA (Low-Rank Adaptation) gibi yöntemler, mevcut modellerin ince ayar performanslarını arttırarak modellerin verimliliğine katkı vererek daha spesifik görevlerde kullanılmalarını sağlar.
Sonuç olarak, büyük dil modelleri, DDİ'nin birçok alanında devrim niteliğinde ilerlemeler sağlamakta ve gelecekte daha geniş ve yenilikçi uygulama alanlarına zemin hazırlamaktadır. Bu modellerin gelişimi ve uygulanabilirliği, dil işleme görevlerinde insan benzeri performansa ulaşmayı mümkün kılmaktadır.Referanslar
1- A. Vaswani et al., "Attention is all you need," 2017
2- Raschka, S. (2023, February 9). Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch.
3- Abdin, A. (2023). How to Fine-tune LLMs with LoRA. https://www.kaggle.com/code/aliabdin1/how-to-finetune-llms-with-lora
4- StatQuest with Josh Starmer, Transformer Neural Networks, ChatGPT's foundation, Clearly Explained -
 DEVAMI
DEVAMIEndüstri 4.0 çağında, üretim süreçlerinde otomasyon ve verimlilik her zamankinden daha önemli hale geldi. Üretim süreçlerinin verimli ve sorunsuz bir şekilde işlemesi için üretim hattındaki cihazların birbiriyle uyumlu bir şekilde çalışması gerekiyor. İşte bu noktada otomasyon endüstrisinde yaygın olarak kullanılan SMEMA Protokolü devreye giriyor. SMEMA protokolüne ek olarak IoT (Nesnelerin İnterneti) teknolojisi kullanılarak üretim hattındaki cihazlar internet aracılığıyla birbirleriyle iletişim kurup, üretim süreçlerinin daha akıllı ve verimli hale gelmesi de sağlanabilir. Blog yazımızda SMEMA protokolünün ne olduğundan, faydalarından ve gerçek dünya uygulamalarında nasıl kullanılabileceğinden bahsedeceğiz.
 SMEMA Nedir?
SMEMA Nedir?
SMEMA 1980’lerde elektronik montaj endüstrisindeki standartları geliştirmek ve ekipman üreticilerini bir araya getirmek amacıyla kâr amacı gütmeyen bir organizasyon tarafından oluşturuldu. SMEMA (Surface Mount Equipment Manufacturers Association) yüzey montaj ekipmanı üreticileri birliği anlamına gelir. Ancak günümüzde bu terim endüstriyel otomasyon dünyasında devrim yaparak otomasyon ekipmanları arasında iletişimi sağlayan bir standart protokolü ifade eder hale geldi. Bu protokol montaj hattındaki makineler arasında uyumlu bir iletişim sağlamak ve farklı üreticilerden gelen makinelerin bir arada çalışmasını sağlamak için kullanılır.
Faydaları Nelerdir?
SMEMA Protokolünün birçok faydası bulunmaktadır bunlardan bazıları şunlardır:- Uyumlu Entegrasyon: Farklı üreticilerden gelen otomasyon ekipmanlarının birbiriyle uyumlu bir şekilde çalışmasını sağlayarak üretim hattının verimliliğini artırır ve entegrasyon maliyetlerini düşürür.
- Esneklik ve Ölçeklenebilirlik: SMEMA, üretim hattının esnekliğini artırır. Yani üretim sürecinde yapılan değişikliklere hızla uyum sağlayabilir ve üretim hattını kolayca ölçeklendirebilirsiniz. Örneğin üretim hattınızı yeniden düzenlemek veya üretim kapasitenizi artırmak için yeni cihazlar eklemek çok daha kolay hale gelir.
- Verimlilik: Otomasyon ekipmanları arasındaki sorunsuz iletişim üretim süreçlerinin daha verimli olmasını sağlar. Üretim hattının daha az duruş süresi yaşamasına ve daha yüksek üretim kapasitesine ulaşmasına olanak tanır.
- Standardizasyon: SMEMA Protokolünün endüstride bir standart haline gelmiş olması nedeniyle ekipmanların ve sistemlerin kurulumunu kolayca yapabilir ve bakımını rahatlıkla sağlayabilirsiniz.
- Senkronizasyon: Protokolü kullanan makineler arasında senkronizasyon sağlayarak üretilen parçaların doğru zamanda doğru yerde olmasına olanak tanır ve montaj işlemi sorunsuz bir şekilde gerçekleşir.
- Hata Bildirimi: SMEMA protokolü hata durumlarını rapor etmek için iletişim mesajları kullanır. Böylece, kontrol sistemlerine hata durumlarını tanımlamak kolaylaşır ve müdahale etmek için bilgi sağlanır.
.png)
Kullanım Alanları ve Akıllı Fabrikaların Yükselişi
SMEMA Protokolü özellikle elektronik üretim endüstrisinde yaygın olarak kullanılır. Yüzey montaj hatları, lehimleme makineleri, test ekipmanları ve diğer otomasyon ekipmanları genellikle SMEMA standartlarına uygun olarak tasarlanır ve üretilir. Bununla birlikte SMEMA Protokolü diğer endüstrilerde de kullanılabilir. Özellikle dijital dönüşümünü destekleyerek akıllı fabrikaların temel yapı taşlarından biri olacaktır. Akıllı fabrikalar üretim süreçlerini optimize etmek, verimliliği artırmak ve esnekliği sağlamak için ileri otomasyon, sensörler, veri analitiği ve yapay zekâ teknolojilerini kullanır. SMEMA Protokolü bahsedilen bileşenlerin sorunsuz bir şekilde entegrasyonunu mümkün kılarak, akıllı fabrikaların işleyişini destekler ve kolayca entegrasyon sağlar.
Gerçek Hayatta Kullanımına Örnekler- Otomotiv Endüstrisi: SMEMA Protokolü kullanarak farklı parça üretim makinelerini ve montaj hatlarını entegre edebilir. Örnek olarak bir şanzıman üretim hattı, bir motor montaj hattı ve bir fren sistemi montaj hattı SMEMA Protokolü kullanılarak birbirleriyle iletişim kurabilir ve koordineli bir şekilde çalışabilir. Böylelikle üretim süreci optimize edilir ve ürün kalitesi artırılır.
- Tüketici Elektroniği Endüstrisi: Bir akıllı telefon üreticisi, SMEMA Protokolü kullanarak farklı üretim ekipmanlarını bütünleştirebilir. Örnek olarak bir PCB (Baskılı Devre Kartı) montaj hattı, bir ekran montaj hattı ve bir pil montaj hattı, SMEMA Protokolü sayesinde bir araya getirilip koordineli bir şekilde çalışabilir. Böylelikle telefon üretim sürecini daha verimli hale getirir ve ürünlerin zamanında teslim edilmesini sağlar.
Gelecek Perspektifi
SMEMA Protokolü, Endüstri 4.0 ve IoT (Nesnelerin İnterneti) teknolojilerinin daha da yaygınlaşmasıyla birlikte daha fazla endüstride kullanılacaktır. Bahsedilen gerçek hayattan bazı örnekler SMEMA Protokolü kullanımının endüstriyel uygulamalardaki önemini ve etkisini göstermektedir. Sonuç olarak bu protokol farklı endüstrilerdeki üretim süreçlerini optimize etmek ve verimliliği artırmak için güçlü bir araç olarak kullanılırken aynı zamanda üretim süreçlerinin dijital dönüşümünü destekleyerek akıllı fabrikaların temel yapı taşlarından biri olacaktır. Gelecekte, SMEMA Protokolü'nün daha fazla endüstride standart hale gelmesi ve üretim süreçlerinin daha da optimize edilmesi beklenmektedir..png)
-
 DEVAMI
DEVAMIGıda üretimi endüstrisi, teknolojinin hızlı ilerleyişiyle birlikte yenilikçi dönüşümler yaşıyor. Bu dönüşümlerden en etkileyici olanı yapay zeka (YZ) teknolojilerinin entegrasyonu ile gerçekleşiyor. Geleneksel üretim yöntemlerinin optimize edilmesi ve verimliliğinin artırılması için YZ endüstriyel gıda üretimini yeniden tanımlıyor. Peki gıda üretiminde YZ nasıl kullanılır?

Gıda Üretiminde Yapay Zeka
YZ birçok farklı alanda kullanılmaktadır. Gıda üretiminde YZ teknolojilerinin nasıl kullanıldığını anlamak için, bu teknolojilerin temel prensiplerine bir göz atalım.
- Sensörlerden Veri Toplama
YZ sistemleri üretim tesislerindeki sensörlerden gelen verileri toplayarak ve analiz ederek üretim süreçlerini gerçek zamanlı olarak izleyebilir ve kontrol edebilir. Bu sayede olası problemler önceden tahmin edilebilir ve gerekli önlemler alınabilir. Örneğin; bir süt işleme tesisi YZ destekli sensörler kullanarak süt kalitesini sürekli olarak izler ve herhangi bir kalite sorunu algıladığında üretimi otomatik olarak durdurur.
- Veri Analizi
YZ üretimden gelen verileri analiz ederek üretim süreçlerinin nasıl optimize edilebileceğini belirleyebilir. Bu sayede üretim kapasitesi artırılabilir, enerji ve hammadde kullanımı optimize edilebilir ve üretim maliyetleri düşürülebilir. Örneğin; bir meyve suyu üretim tesisi YZ algoritmalarını kullanarak üretim verilerini analiz eder ve meyve suyu karışımlarını optimize eder. YZ mevcut meyve stoğu ve talep verilerine dayanarak en uygun meyve karışımlarını belirler böylece hem müşteri taleplerine daha iyi yanıt verir hem de üretim maliyetlerini minimize eder.
- Otomatik Süreç Optimizasyonu
YZ üretim süreçlerini otomatik olarak optimize ederek daha verimli ve tutarlı bir üretim yapılmasını sağlayabilir. Bu sayede ürün kalitesinde ve enerji verimliliğinde önemli bir artış sağlanabilir. Örneğin; bir ekmek fabrikası YZ destekli bir sistem kullanarak üretim süreçlerini optimize edebilir. Kameralar ekmeklerin pişme sürecini sürekli olarak izler ve YZ algoritmaları bu görüntülerden fırınların çalışma sürelerini ve sıcaklıklarını optimize eder ya da YZ ekmeklerin kızarma seviyelerini analiz ederek ideal pişirme süresini belirler ve fırınların ayarlarını buna göre düzenler. Bu şekilde her seferinde tutarlı bir kalitede ekmek elde edilirken enerji tüketimi de en uygun seviyeye indirilir. Ayrıca YZ sürekli olarak yeni verilerle öğrenir ve üretim süreçlerini sürekli olarak iyileştirir böylece fabrika sürekli olarak en verimli şekilde çalışır.
- Ürün Tasarımı ve İnovasyon
Gıda mühendisleri YZ algoritmalarını kullanarak yeni ürün formülleri oluşturabilir ve mevcut ürünlerin kalitesini artırabilirler. Tüketici taleplerinin analiz edilmesine yönelik özel ürünlerin geliştirilmesi gibi süreçleri YZ destekli sistemler geliştirilebilir. Örneğin; bir dondurma şirketi YZ algoritmalarını kullanarak yeni lezzet kombinasyonları geliştirebilir. YZ müşteri tercihleri ve pazar trendleri hakkında verileri analiz eder ve benzersiz dondurma tatları önerir. Örneğin; meyve aromalarıyla çikolata tatlarını başarılı bir şekilde birleştiren yeni bir dondurma çeşidi geliştirebilir. Bu sayede, şirket müşterilere daha çeşitli ve ilgi çekici ürünler sunabilir.
- Gıda Güvenliği ve Kalite Kontrolü
YZ gıda üretim tesislerinde hijyen standartlarını izleyebilir ve denetleyebilir. Ayrıca ürünlerin üzerindeki kalite kontrolünü artırarak hatalı ürünlerin tespit edilmesini sağlayabilir. Bu şekilde gıda güvenliği ve tüketici sağlığına yönelik riskler azaltılabilir. Örneğin; bir dondurulmuş gıda üreticisi YZ destekli bir görüntü tanıma sistemi kullanarak ürünlerin ambalajlarındaki hasarları tespit eder ve hatalı ürünlerin otomatik olarak ayrılmasını sağlayabilir.
- Tedarik Zinciri Yönetimi
YZ tedarik zincirini optimize etmek ve gıda israfını azaltmak için kullanılabilir. Ürünlerin tedarik zincirindeki hareketleri takip edilebilir ve stok optimizasyonu yapılabilir. Örneğin; bir sebze ve meyve işleme tesisi YZ destekli bir tedarik zinciri yönetim sistemi kullanarak taze ürünlerin envanterini takip edebilir ve optimum depolama koşullarını belirleyerek israfı minimize edebilir.

Yapay Zeka Teknolojilerinin Zorlukları ve Gelecek Beklentileri
YZ teknolojilerinin gıda üretimi endüstrisine entegrasyonu, bazı zorlukları da beraberinde getirir. Büyük veri işleme kapasitesi, altyapı gereksinimleri ve güvenilirlik konuları gibi zorluklarla başa çıkabilmek için endüstrinin neler yapması gerekiyor? Bu zorluklar ve çözüm önerileri şunlardır:
- Büyük Veri İşleme Kapasitesi: YZ sistemleri büyük miktarda veriyi işlemek için yüksek işleme kapasitesine ihtiyaç duyar. Bu sorunun çözümü için üretim tesisleri yüksek performanslı bilgisayar sistemleri kurmalıdır.
- Altyapı Gereksinimleri: YZ sistemlerinin kullanılabilmesi için gerekli altyapının ve uzmanlığın oluşturulması gerekir. Bu nedenle üniversiteler ve özel eğitim kurumları YZ ve gıda üretimi alanlarında uzmanlaşmış eğitim programları ve kurslar açmalıdır ayrıca YZ konusunda uzman firmalar gıda üretim tesislerine danışmanlık ve çözüm sağlayabilir.
- Güvenilirlik: YZ sistemlerinin güvenilir ve doğru sonuçlar vermesi son derece önemlidir. Bu nedenle YZ sistemleri gerçek üretim verileri ile test edilmeli ve doğruluk oranları belirlenmelidir. Ek olarak YZ sistemlerinin etik ve şeffaf bir şekilde kullanılması veri güvenliği ve algoritma şeffaflığı gibi konularda gerekli önlemlerin de alınması gerekir.

Sonuç
Gıda üretimi endüstrisinde YZ teknolojilerinin entegrasyonu sadece bir dönüm noktası değil aynı zamanda geleceğe yönelik heyecan verici bir yolculuğun da başlangıcıdır. Bu teknolojiler endüstriyel süreçlerin optimize edilmesi, ürün tasarımı ve yenilikçilik süreçlerinin desteklenmesi ve gıda güvenliğinin artırılması gibi alanlarda devrim niteliğinde değişiklikler sağlıyor. Ancak bu dönüşüm sürecinde karşılaşılacak zorluklar da göz ardı edilmemelidir. Büyük veri işleme kapasitesi, altyapı gereksinimleri ve güvenilirlik gibi konular YZ teknolojilerinin başarılı bir şekilde entegrasyonunu desteklemek için ele alınması gereken önemli hususlardır. Gelecekte YZ teknolojilerinin daha da gelişmesiyle birlikte gıda üretimi endüstrisinde daha büyük ve daha dönüştürücü değişikliklerin yaşanması beklenmektedir. Gıda üretimi endüstrisinin geleceği YZ ile daha parlak ve daha yenilikçi bir şekilde şekillenecektir.
Görüntü işleme, dijital görüntülerin analiz edilmesi ve işlenmesi için kullanılan bir teknoloji dalıdır. Görüntüleri iyileştirme, objeleri tanıma ve desen tespiti gibi işlemlerle birçok alanda önemli katkılar sunar. Sağlık sektöründe tıbbi görüntü analizi, güvenlik alanında yüz tanıma sistemleri ve otonom araçlarda çevre algılama gibi uygulamalarda sıkça kullanılır. Yapay zeka ve verimli algoritmalarla birleştirilen görüntü işleme, görsel verilerin anlamlandırılmasında önemli bir rol oynar.